Archiving the user experience of the Internet: Does it matter?
Over the last couple of days I've read two blog posts that touch on the subject of archiving the digital experience of the Internet.
Nick Sweeney wrote about what Bagpuss can teach us about the Internet. He talked about how whilst the engineering mice could get a lost item restored to working order, it was the whole cast of characters that imbued the object with narrative. He went on to explain that it is this narrative and context that is missing when we try to archive the digital experience.
Chris Applegate also wrote about archiving the web in his round up of thoughts from Open Tech at the weekend. He made the point that:
"The obsession with archiving now has struck me as somewhat odd - we live in era where storage space is near-infinitely abundant and yet we are more worried about losing our culture than any other age in history. Did the scribes of the Lindisfarne Gospels factor in the possibility their work would still be around 1,300 years in the future?
...
As information has become less scarce, paradoxically we've become increasingly obsessed with preserving it. Maybe it has something to do with the volatility of our storage - all it takes is your hard disk to be corrupted and you could lose years of your work. Or the effect of the internet on giving us information at our fingertips means we're now capable of knowing what we would lose if these archives disappeared. Or maybe it's just hindsight and a selective memory - we lament all those thoughtlessly-wiped episodes of Doctor Who, and are now much more sensitive to data loss, but we're not so fussed about all the editions of The Cliff Richard Show that got deleted too."
Which is possibly a little unfair on Cliff Richard fans, who you'd suspect lament missing episodes with an equal fervour, but I take his point.
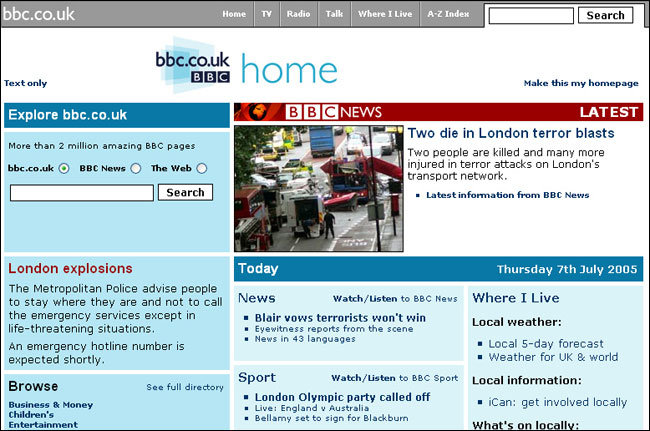
Our failure to adequately capture what the early web was like, though, is something that has bothered me for some time. One of the first of my trademark multi-post web review series was about the earliest BBC Online content still hanging around on the BBC's servers, with content that covered the 1995 and 96 budgets, and the death of Diana and politics in 1997. I've also blogged about the history of official Doctor Who content on the BBC website, and how bbc.co.uk responded to the 7/7 bombings in London.
I recently wrote about the way that whilst we've retained the Guardian Unlimited content from tournaments like Euro2000 or the 2002 World Cup, we've ported a lot of content into new templates and new formats, so haven't preserved the whole feel of the site in the way that an aged copy of the newspaper does.

And whilst I worry about what big media sites are doing, I've completely failed to capture my own archive. Since I started blogging in 2002, this site has had at least three designs that I've got no proper screenshots of whatsoever.

Of course, as Chris says, it may not matter in the end.
Whilst it is difficult, for example, to recreate the exact experience of loading a game from cassette on the ZX Spectrum with the bytes being represented by the yellow and blue flashing border, you can still play Manic Miner on the web. And the legacy of that machine isn't in recreating the exact experience, but in the generation of bedroom programmers that the machine and others like it spawned.

Even if it isn't possible to perfectly archive or recreate it, the legacy of the early Internet is the pervasive use of networked digital technology all around us.
I'm not sure that the difference between playing a ZX Spectrum game on a simulator and using the real thing is quite as small as you paint. To understand the legacy of the early Internet, you need to understand the culture which includes the tactile and aesthetic experience of using early computers along with the context in which they were used (e.g. plugged into a family TV at odd hours of the day when others weren't watching it because TV wasn't 24 hours).
To take an analogy closer to home: how similar or different is reading a story from The Times from the early nineteenth century on screen from looking at an original hard copy? Even an on-screen digitised version which gives you layout doesn't give the same sense of size, shape and with that the implications about how easy or hard papers were to make, the context in which they were read and so on. The changing size and shape of newspapers, for example, tracks wider changes in society (less time reading at home, more time reading when commuting etc.) - and seeing the original physical form adds significantly to only reading words on screen.
You make a good point Mark. Having the Spectrum was the main driver of me getting my first hand-me-down tiny telly in my own bedroom. I think my parents were sick of having the computer on downstairs all the time!
Thanks for the link, Martin. Picking up on Chris's point, I think that there are a couple of impulses at work. One is tied to the appreciation that the amount of stuff being created is immense, but hard disk space is cheap and the technical ability to keep it around seems trivial. We're long past the old equation where the cost of creating texts and maintaining archives meant that everything preserved is, by definition, of value, because value is invested in its keeping.
The other is an understanding that it's very, very easy for chunks of web history to be vanished out of online existence when their creators die, or after something as trivial as an unpaid domain registration, and it's not the gradual curve of loss or degradation that exists with tangible or analogue archives. It's capricious and uneven and shocking when it happens. It taps into the Orwellian "who controls the past, controls the future."
There's always a gap between how people remember a particular period and what the archive records of it, and that's not problematic, especially now that social history gives weight to ephemera and personal accounts. But if you wanted to describe the web (or just a part of it, say, weblogs) as things stood ten years ago, I'm not sure you'd have the source materials or the archival tools to do it, and you'd still need contextual assistance along the lines Mark Pack mentions. You could describe it in a tapestry of remembrances, but they'd mainly be [citation required] material. (It's ironic that the verification standards of the web's primary accumulator of explanatory content are often ill-suited to the web itself.)
In technical terms, it's a version control problem on a grand scale, which is what James Bridle was describing at dConstruct. Sticking with that analogy, it's also a CHANGELOG problem, because changelogs provide rationales and justifications which are important for ideas of legacy and iterative development in the digital world. Otherwise, you have the equivalent of litigation without precedent, in which arguments are carried out in the here and now, constrained by a relatively shallow depth of field.
My own take on this is that there are two separate issues.
The first is the continued relevance and discovery of archive content. This can only be fully realised if that content is treated in the same way as new content and made an integral part of every discovery mechanism that applies to new content. So the metadata must be brought up to date, old taxonomies mapped to new ones and archive content made a first class citizen of the site in which it forms a part.
The second issue is maintaining a record of what something was like at the time. I'd argue that doesn't need to be a complete experience, but that may just be me not dreaming big enough :) Yes it's important to be able to see that, but there are other ways of showing it, whether through the archive content itself (which is as much about the time as it's primary subject) or representative samples.
But what's more important is ensuring the content remains accessible and relevant. You can't walk around an ancient library, but you can read a lot of the works. Some of them even have ISBNs.