London Linked Data meet up: Notes and take-away quotes - part 1
Last week I attended the first London Linked Data meet-up. It was organised by Georgi Kobilarov and Silver Oliver, and they kindly invited me to speak on a panel about 'Linked Data and the future of journalism'. Earlier this week I published a two part rough transcript of my contribution to that debate.

Today I wanted to publish the first of two posts looking at what I made of the rest of the event, which was, at times, a little bit out of my sphere of technical comfort.
'Keep up the good work' - Leigh Dodds
As well as appearing alongside me on the 'future of journalism' panel, Leigh Dodds gave his own talk, which was essentially along the lines of a gee-up for the community. As well as saying 'keep up the good work', Leigh had some suggestions for how to take the 'Linked Data' community to the next level. He was keen to see people open sourcing their code as well as their data, so that as projects ran out of steam, they could be picked up and incubated by other people. He wanted the ability for people to 'gather around processing the same set of data', rather than having three different projects working in the same area, some of which were bound to become 'moribund'.
Semantic search and browse
I found a lot of the afternoon to revolve around the theoretical and conceptual, with at the moment a distinct lack of real world applications to demonstrate the usefulness of the approach. Richard Cyganiak made the point that we have lots and lots of linked data now, and we even lots of infrastructure for processing the data, but there are not as yet as many tools for people to really start exploiting and using it.
He showed us things like Marbles, which is "a server-side application that formats Semantic Web content for XHTML clients", the Tabulator browser (or Firefox add-on), and Zitgist. He also showed us semantic web enabled people finding search engine sig.ma. As he explained it, if you weren't happy with the results of your vanity search, it meant you needed to put some RDF and FOAF on your homepage to fix it.
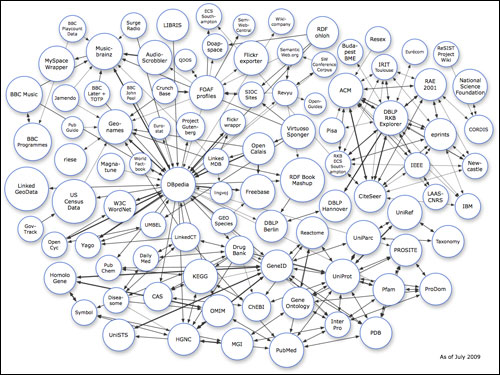
Richard is also one of the people maintaining the linked data universe diagram that cropped up a fair few times during the day.
Freeing Government data - in the right formats
The penultimate panel of the day was discussing the freeing of 'Government data', and featured Nigel Shadbolt and Tim Berners-Lee. They were refreshingly candid about some of the problems they faced. There was a description, for example, of how they kept having to strike-out the words "the database" in civil servant papers and replace it with "the data".

One question from the floor suggested that this was all very 'flavour of the month', and would, with a potential change of Government in the offing, fall by the wayside like previous eGovernment metadata initiatives had. The panel felt that currently this was a bottom-up initiative, rather than the top-down 'tablets of stone' of yore. It was explained that a 'hospital' meant something very different to the army and to the NHS, and by using RDF both definitions could happily coexist at the local level.
One of the central issues we all face in trying to use 'civic data' is the peculiar situation the UK finds itself with digital versions of geographic data all being locked up in one copyrighted store. The panel pointed out that there are no standard URIs for constituencies. If the BBC and newspapers all used the same set of data nodes, it would be easy to aggregate all of the content about a particular local election campaign, although, as Brendan Quinn sitting next to me wryly observed - "That's fine - but would the publishers want you to do that?"
Perhaps the shrewdest question from the floor was the one that pointed out: "You seem to be dealing with a set of cultural, legal and technological problems. Can any one of them be solved alone?"
Tim Berners-Lee exhorted the audience to keep making cool mash-ups to show the potential of 'Linked Data', and to build a way of parsing PDF documents into the RDF data format. Paul Miller finished with a brilliant plea:
"I don't want to see mash-ups that are on the technological cutting edge. I want them to be compelling."
The RDF wars
As an aside during this session there was a brief outburst of 'the RDF wars'. As an outsider, I find the zealotry around the arguments fascinating. The Guardian's Data Store got pulled into the debate. Mischa Tuffield argued that because the individual cells in the published Google Spreadsheets were addressable, this qualified as 'Linked Data'. Equally passionate was the argument that without the corresponding RDF, what The Guardian publishes might be 'open' data, but it isn't 'linked' data.
On the panel, Mark Birkbeck was unequivocal:
"RDFa is the solution to everything. Including problems we haven't yet thought of."
Me?
I just kept my head down and hoped that I wouldn't get asked about it when I was on my panel. Personally I think that if you show a journalist a spreadsheet, they understand how it works and how to publish. If, on the other hand, you show them some RDF, the most likely response will be 'WTF?'.
Next...
In my final post about the London Linked Data meet-up, I'll have some more of my observations of the event, including my notes on a talk by Andrew Walkingshaw, and the omnipresence of the BBC throughout the day.
Read more of my articles about notes and quotes from media and web events and the future of news
Regarding the Guardian Data Store, @tommyh clarified on Twitter: "re the spreadsheet cells, i think my comment was 'they're Linkable Data, but not Linked Data'"