“The IA of /Culture” - Martin Belam at EuroIA 2011
This is the essay version of the talk I gave at the 2011 EuroIA Summit in Prague. You can download this and all of my EuroIA 2011 blog posts as one printable PDF or for iBooks.
For those of you that don’t know, the Guardian is a left-leaning serious newspaper based in the UK. It was first published in Manchester in 1821, and we’ve been publishing on the web since November 1995. We’ve got quite a large website now - with 1.37m articles at the last count. We publish roughly 400 pieces of new content every day, and we’ve recently launched a US edition, as we expand with a New York based digital office.

Today I want to look at a case study of a rolling project that has last around 18 months at the Guardian called “Arts mutualisation”.
Mutualisation?
Well, in the UK, there is a tradition of the “mutual” organisation. A group of consumers gather together and all agree to purchase a certain type of service from one provider, and the funds they spend in return allow that company to provide the service. The Guardian’s editor, Alan Rusbridger, has suggested that this might become a sustainable model for journalism in the future - where news is produced not simply as a consumer product, but in a way that benefits and involves the audience, and allows them to benefit the news organisation.
When exploring the idea, Rusbridger has typically used an example from the arts. He argues that on the opening night of a major new production in London, the Guardian will send Michael Billington, our distinguished theatre critic of many years. However, as authoritative and learned as he undoubtedly is, Michael surely can’t be the only voice worth hearing from that audience. Many other people who have made the effort to attend the opening of a new production must also have interesting critical perspectives to give.
In presentations, Rusbridger has sometimes used this picture by Alastair Muir to illustrate his point.

Taken at Dave St-Pierre’s Un Peu de Tendresse Bordel de Merde, earlier this year, our editor says wouldn’t it be brilliant to find out what the couple in the bottom right-hand corner of the photo thought. Or the rather excited chap in the middle.

The challenge for us, therefore, was to work out how we could transform our site into a space where these kinds of conversations and discussions could be facilitated - “Arts mutualisation”
You see, there is a major problem in the way that the press covers arts and cultural life.
Nearly all reviews are based on experience of the performance or recording or book in a pre-release, preview or advanced timeframe. This means that at the time you review a movie, it is pointless asking for audience reviews, because they haven’t seen it yet. At the time you review an album, probably the only people who have heard it will be those who have illegally downloaded it in advance. And the problem is particularly critical in books, where often serious tomes are reviewed in advance of their publication in hardback, when they won’t become commonly stocked in major stores until the paperback editions follows later.
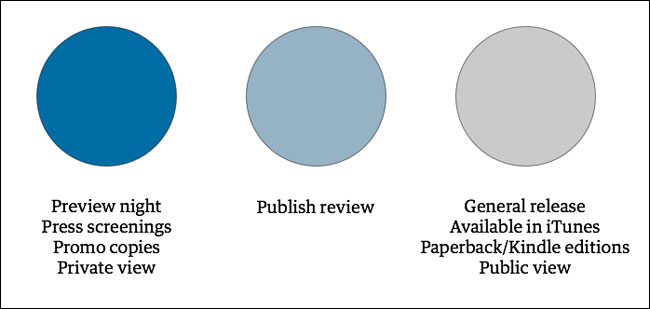
You can visualise the problem as a pyramid. A few critics, with access to the means of mass publication, are able to review a few cultural works, often in advance of the audience being able to experience them.

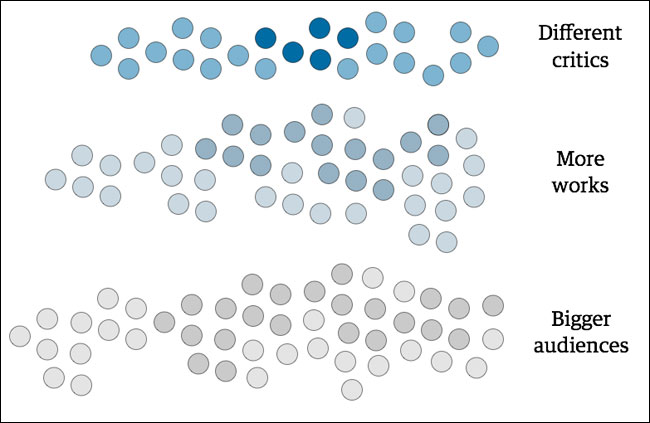
We wanted to make three changes to that pyramid.
At the level of the critics, in an era of widespread self-publishing via the web, we wanted to increase the range of voices on the Guardian website.
At the level of works, we wanted to increase the number of works that were being reviewed and discussed. The Guardian simply doesn’t have the resource to cover every theatre opening, gallery exhibition, music release or book in the UK, let alone internationally.
And, by enabling a broader discussion, we hoped to grow our audience.
Pointing at things
One of the immediate questions was, if we are going to facilitate all of these new conversations and reviews, where do we “hang them”? Where do they belong? If I write a review of Kraftwerk’s “Radioactivity” album, how do we link it to other reviews of that album, or other reviews of Kraftwerk, or other reviews of artists related to Kraftwerk.
Inspired by the world of linked data, permanent URIs and beautiful unique identifiers, we decided that robots must be the answer.
(Although, in fairness, if you’ve known me for a while, you’ll be aware that I’ll often suggest “Robots are the answer!” to just about any query)
Using MusicBrainz as a key
To get the project started, we gave some developers some time to see what they could come up with in terms of an automated music page. We gave them a very rough brief - no more than a sketch on a whiteboard, and set them to work.
One of my sketches from the project.
They amazed us by very quickly building a prototype of a page that aggregated information about an artist from every imaginable source, including Amazon, YouTube, Last.fm, Gigulate, Soundcloud. And, of course, using our API, the Guardian’s own music content. Not only did they make a series of pages for the demo, they built the system in such a way that simply adding a new MusicBrainz ID onto the end of the URL would refresh the page to feature that artist, with the data aggregated on demand.
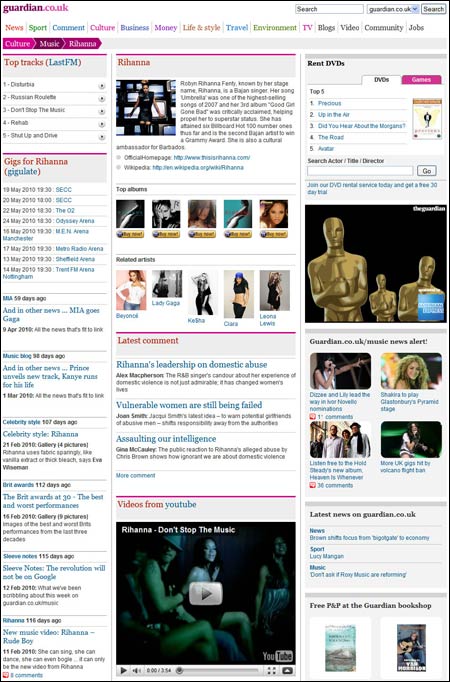
An internal prototype of an aggregated music page from 2010.
Having seen the potential, we set out to build something similar for our books site. We bought in a whole set of data about Books.
And struggled.
What did we do wrong?

We ended up designing and trying to build the books site for what seemed like an eternity. One of the fundamental issues we faced was that the domain model for books is fiendishly complicated, and we never really got to grips with it. We also made some mistakes in the process of the project.
Ignored previous experience
After we’d got a little way into the project, we were joined by a new team member, who had been involved with similar work on another website. They explained that using the ISBN as the key identifier was going to give us a whole world of pain. I didn’t listen. You see, books go in libraries. And IAs are the librarians of the internet. So how hard could this be?
To their credit as a person, they have resisted the temptation to say “I told you so” to me every single time they have seen me since.
Unlike MusicBraninz IDs, ISBNs have been around for years and years, and are rooted in the physical world of retailing physical books. They were not designed as a digital identifying system, and consequently they do that very badly indeed. You can’t group editions around a single work, and most books have multiple editions. And sometimes publishers change the cover without changing the ISBN. And you can’t identify the elements that make up anthologies. And they also give ISBNs to audiobooks on CD. And to pop star calendars. And to a company that specialise in doing print-on-demand versions of Wikipedia pages. And to the cardboard promotional displays that go in shops to hold books. In short, as an unique identifying system, they are one of the worst that I have ever come across. And I’ve been an IA for a long time, and seen a lot of bad classification systems.
Too few developers in too big a team
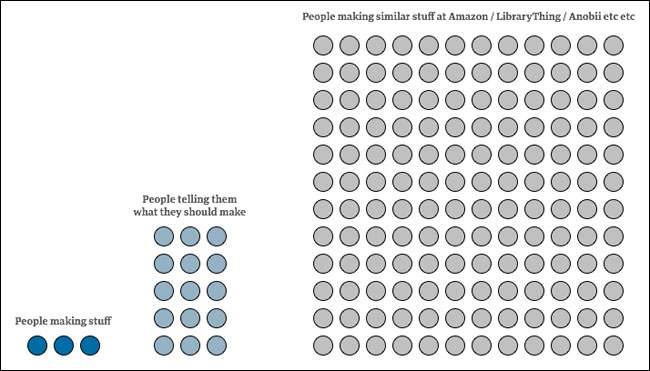
At times the project team consisted of three people “making” things by writing code. And around fifteen people telling them what to make. Fifteen people can change their minds about what they want much faster than three people can make it.
With that level of development resource, we were always going to be at a disadvantage to services like Amazon or LibraryThing or Anobii who have bigger dedicated development teams.
Obsessed over design details
We spent a long time stuck in a vicious loop of constantly refining the visual design on paper. With a large group of stakeholders, design reviews were done weekly, really slowing down the product definition process. And all the time we were pushing around theoretical pixels, we were losing time when code could have been written.

The final design of one of our automated book pages.
Big bang launch
Having failed to meet several launch deadlines, we still ended up going for a “big bang” launch and reveal of the new pages and functionality. We would have been much better off gradually and incrementally adding features to the site.
What did we do right?
It wasn’t all doom‘n’gloom however. There were some things that we did really well, and we learned and improved our product development process as we went along.
Lists: Objects, properties, actions
One area of the site where development went very well was with our “lists” functionality. This was built as a standalone app, and we worked hard to model it. I used an “Objects / Properties / Actions” map to specify the IA of lists. For example, a “List” is an object which has the properties “Unique URL” and “Name”, and the actions that can be performed on the “List” are “Add book”, “Remove book”, “Re-order list” and “Clear list”.
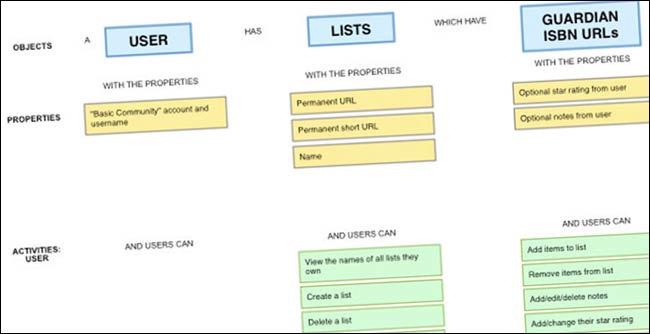
I find this way of mapping out functionality to be really helpful in clarifying exactly what needs to be built. It also, once you think about which three action buttons would appear on a mobile version, helps you prioritise functionality.
On the Guardian site users can now make lists around books and music, and we hope to add more community functionality and serendipitous discovery around lists in the future.
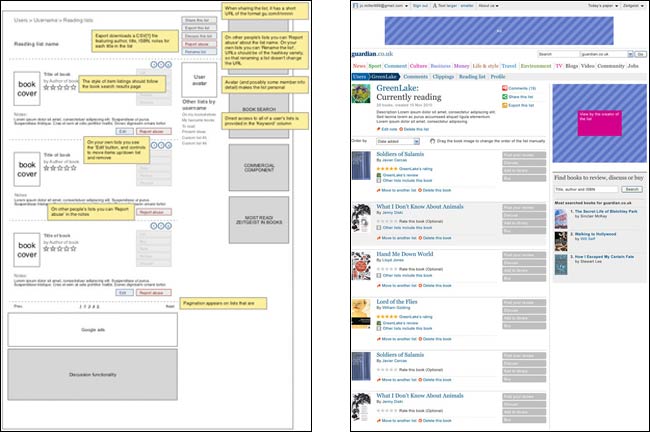
My ugly wireframe, and Akemi’s elegant design for our lists functionality
Gave the developers a chance to be creative again
For the SXSW Festival, we paired up some of our developers with journalists like Rosie Swash and Jemima Kiss, and sent them off to do “stuff”. One of the things they worked on was a refined version of the linked data music artist pages, this time based around who was playing at the festival. There was much less involvement from the design or UX team - instead there was simply an opportunity for the developers to code something that would work in the production environment.
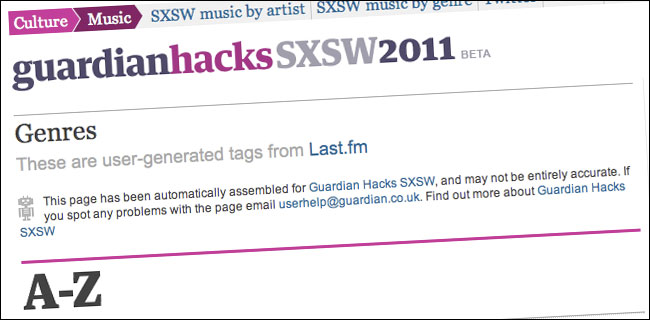
A prominent disclaimer makes it clear that the pages are automated by robots, not curated by Guardian staff.
We’ve then moved on to launch those pages for real, and got back into the habit of rapidly iterating and adding functionality. It means that sometimes our audience has complained that the work seems “unfinished” - for example we launched artist pages, then album pages, then a way to search through them. I’m comfortable with releasing things that don’t quite add up to the full product - it isn’t as if the Guardian website is starting from scratch. However, it seems that there is some education work to be done on the web audience about the benefits of agile software processes, as well as in boardrooms.
Increased direct community engagement
The new designs have brought our community activity to the forefront of our website. The Books front has a panel that calls out recent community interaction, and the weekly “Tips, links and suggestions” thread makes a place where the community can converse directly with staff. Overseen by one of our “community co-ordinators”, it is a model that we are beginning to export around the rest of the site.
Comment is free, our online home for opinion and debate, now has a similar panel, as does the new music front which we launched just this week.
What are we not sure about?
There are some areas of the project where the jury is still out...
Beware of “Panda”
If you’ve seen Mike Atherton’s talk “Beyond The Polar Bear”, you’ll know that the BBC has claimed some great SEO success with densely interlinked automatically generated pages about food, music, sport and television & radio programmes. We expected to see the same. Actually, we now think that the addition of these pages are potentially an SEO danger for our site.
Look at it this way - as I mentioned earlier we have 1.37m pieces of original quality content on the Guardian site. And prior to this project, the site consisted 100% of that type of content. Throw in the automatic books and music pages and suddenly those 1.37m URLs are potentially swamped by 3m artists and 8m books. On crude numbers alone, the original content on our site begins to look like the exception rather than the rule.
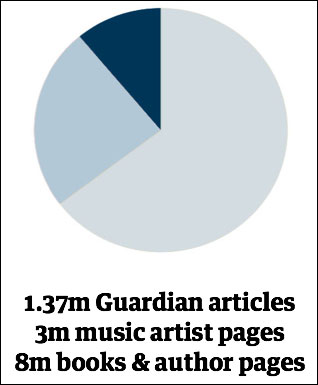
We’ve ended up excluding the automatic pages from search indexing, as we think they risk tripping Google’s “Panda” update algorithm, and damaging the authority of our domain name within search.
Searching for search
With the discoverability of the pages limited from the outside world, our own navigation structures become more important. We’ve taken two different approaches to search. On the books site, you can search by author, title or ISBN, and the results are delivered on a standalone SERPs design. This is a full-text search with partial matching. On the music site, search is restricted to artist names, and the results are delivered inline on the right-hand side of the page. Due to technical constraints, neither the automated book or music pages appears within the main Guardian site search. Making this more consistent will require more technical resource.
It is a fascinating example of where a concern for overall UX consistency and coherence in a visual design can be subsumed by the agile methodology of valuing “working code” above all else, especially in projects that work in silos. Given the user story “I want to be able to easily find the page of an artist I’m looking for”, the search box in the right-hand side of a music page is a perfectly good piece of working software. However, if you rephrase the user story as “When I type the name of a band I am interested in into the Guardian’s search box, I want to find all the pages on the site about them”, we’ve clearly got some way to go.
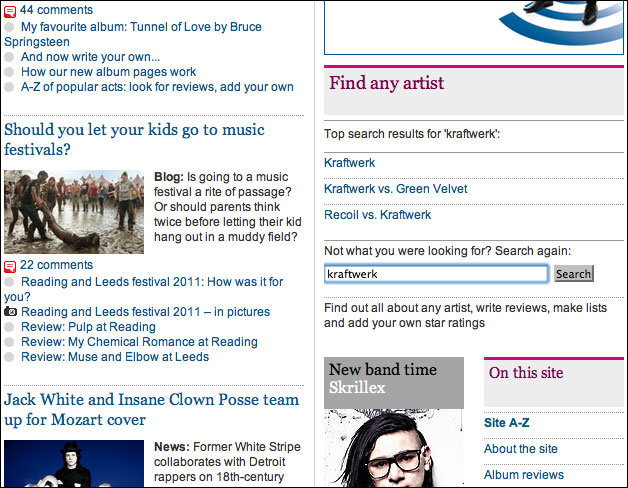
Inline music search on the Guardian website
Maybe it wasn’t a technical problem anyway?
Over this summer, the Guardian Books blog ran a brilliant series called “Summer Readings”, where members of staff could write a piece about a specific book they remember reading during a summer. It brought contributors into the book site who normally write for other areas, and gave users a series of reflections on a wide range of book genres. Each of the blog posts linked through to one of the relevant automatic pages for that title. Did that link alone stop it from being a “top-down” editorial exercise though? The Books blog audience themselves were not invited to participate.
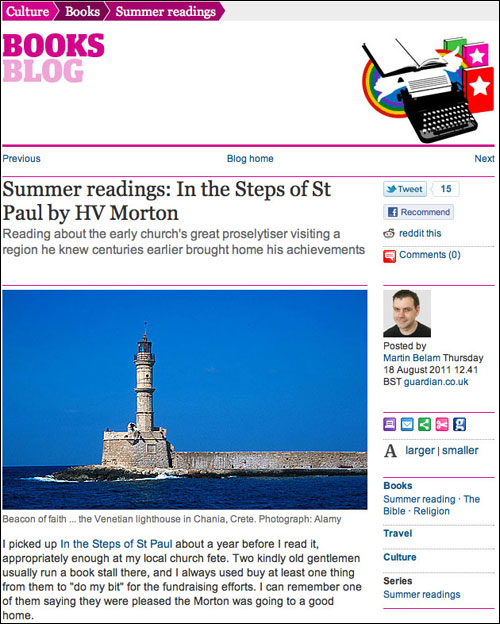
Now, I totally understand why that would be the case. The production process would have been onerous. A smaller book blog might get a handful of submissions, and whack them up online in a WordPress theme, regardless of any bad spelling or obsessions with self-published vampire novels.
The Guardian can’t do that. At the very least all of the submissions would need to be sub-edited for howling spelling errors, and, as we have learned the hard way from reviews posted to our brilliant Children’s Book site, checked for plagiarism. And that is before you upload them into our CMS, keyword tag them, make a contributor profile, write a standfirst, schedule them, then promote them...
Maybe the technology aspect of “mutualisation” has been a distraction from the much harder transformation needed to workflows and editorial processes, and we got distracted by the promise of shiny robots?

Conclusion
I always like to finish a talk with some concrete lessons - so here are the five things that I think are worth taking away from this case study.
1: Know what is important
A failure to set clear project goals is one of the easiest ways for digital projects to go astray. On the “arts mutualisation” project we’ve clearly met the goal of having lots of new automated pages. But is that the thing that will achieve the stated aim of making the Guardian’s cultural coverage less “top-down”? It certainly facilitates new types of interaction on the site, but it remains to be seen how widely they will be adopted. both by the end users and during the content production process. With more measurable metrics, faster iterations, and more data-driven decisions, we might have ended up building different functionality.
2: ISBNs are evil
Just to be clear: ISBNs are fucking evil.
OK, to be fair, they aren’t evil. They are just ill-suited to a digital world.
The evil bastards.
3: Trust good developers
I always argue that the software developers are your key allies on any project. You can design the most amazing interactions and user flows in the world, but it is the way that the code handles them that will ultimately define the true “user experience”. Bring developers into project meetings early. If they are telling you something is hard, listen to it as a warning sign. If they are telling you that they can take a shortcut if only you change this tiny thing here, make sure you really weigh up the benefits and costs of making the small change. Above all empower developers to make decisions and give them the space to be creative. Coding to an ill-informed rigid spec must be one of the most soul-sucking jobs there is. Being invited to be inventive with software must be one of the best. Make sure your developers have the latter job.
4: Listen to all of the team
Your job description might say that you “own” the user experience, or “own” the information architecture of a web service, but you are never going to “own” all of the relevant experience for any given project. Use the members of the project team around you for the knowledge and skill that they bring to the table. Don’t dismiss people because of their age or gender or that they have less overall experience than you - if they have domain expertise, you would be a fool not to learn from it.
5: Get the model right
I think the single biggest lesson for me out of this project was the absolute importance of getting the model right when making a web service. At the Guardian I’ve been very lucky because the domain-driven design of our CMS, and the focus that having an API gives us, means that for content our “model” is very tightly defined. For books, the model of author, work, edition, translation, anthology, compilation, abridged and so on is horribly complicated. Music was simpler, but even mapping the relationship between John, Paul, George and Ringo is complex.
If IA means anything in a world where simply everyone is UXD, then getting this fundamental right is our thing.
Thank you and acknowledgments
I’ve had the benefit of working with a great team on the mutualisation project over the last 18 months. There are too many to name all of the people who go into a piece of work like this, but I’d particularly like to thank Daithi Ó Crualaoich, Gideon Goldberg, Lisa van Gelder, Matt Andrews, Robbie Clutton, Mark Hunter, Theresa Malone, Hannah Freeman, Piers Jones, Carrie Smith, Meg Pickard, Aidan Geary, Tara Herman and Stephen Abbott.
This is one of a series of blog posts about EuroIA 2011 in Prague. You can download all of the blog posts as one printable PDF or for iBooks.
All your EuroIA 2011 slides are belong to us
“Designing today’s web” - Luke Wroblewski
“The IA of /Culture” - Martin Belam
“Navigating the Digital Spice Route” - Terry Ma
“Extending the Storytelling - Blending IA and Content Strategy” - Boon Sheridan
“Pervasive IA for the Sentient City” - Andrea Resmini and Luca Rosati
iPads, kids and design lessons for adults - Wouter Sluis-Thiescheffer & Brian Pagán
“Understanding the Nature of Resistance” - Alla Zollers
“Does a Rich GUI Make the Bank Richer?” - Haakon Halvorsen & Kjetil Hansen
“Designing for Everyone, Anywhere, at Any Time” - Anna Dahlström
“Truth and Dare – Out of the Echo-Chamber, into the Fire” - My critique of Jason Mesut at EuroIA 2011
“The Rise and Fall...and Rise Again of Information Architecture” - Bob Royce
“Fill in the IA gap” - Mags Hanley
You might also be interested in:
All your IA Summit 2011 slides are belong to us
All your UPA 2011 slides are belong to us
All your EuroIA 2010 slides are belong to us