“Come as you are” - Part 2: The BBC years
I got my first proper digital job at the BBC in 2000, working as a Registration Co-ordinator. I kept the clipping of the job advert that I replied to. [1]

There seems something really quaint now about checking the printed newspaper once a week for new media jobs until I saw one that I thought I could apply for. This really was a case of “Come as you are”. I’d made some websites, I had some technical knowledge, and I understood the principles on which search engines worked. There was no qualification you could get in SEO, and to be honest, the BBC didn't really understand that it was SEO. Hence the oblique job title.
I was recently prompted to blog about my early SEO years at the BBC having seen Chris Moran talk about how he does editorial SEO at The Guardian. My role revolved around submitting content to a variety of search engines that you've probably forgotten or never heard of - HotBot, Lycos, Teoma, Looksmart and Inktomi - as well as getting content listed in the Yahoo! directory. Rather than everything being crawler or site map based, this often consisted of submitting an actual URL of new content through a webform.

Read the full blog post: “SEO at the BBC - The early years”
In that role I didn’t just look at external search engines, but also at the BBC’s own internal search, which had a very poor reputation. The technology, Muscat, wasn’t configured well, and a lot of BBC Online content was in different silos where it couldn’t be indexed. Notably, BBC News content was excluded from the site wide search.
We had a rudimentary “best bets” system though. We answered incoming mail from the feedback link on the search results pages, much of which was along the lines of “Dear BBC, I was using your search to look for the Panorama programme. I typed in ‘panorama’ and I did not find the programme. This is a national disgrace, yours angrily etc etc”. And so we would find the URL of the Panorama programme website, and enter it into a spreadsheet, next to the search terms we thought it should appear for. This was periodically uploaded to a server, and at query time these best bets would appear.
The BBC began to realise that search was a key part of navigating their vast quantity of websites, and decided to invest in it as a project. This was the first time that I was exposed to user testing, as several different search designs were put in front of users. I think there is something astonishingly powerful about witnessing a user testing session and really realising for the first time that “you are not your users”.
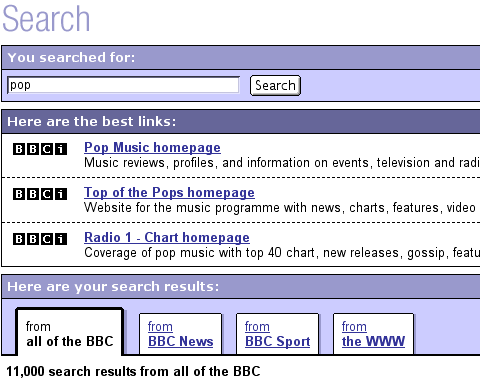
The lilac BBCi search result pages from 2001
One of the outputs of that project was a more sophisticated taxonomy and taxonomy management tool to power search best bets across BBCi, as it was then being rebranded. That project also introduced me to personas for the first time, and the software was known as “Bromsgrove”, because that was where the primary target audience persona lived.
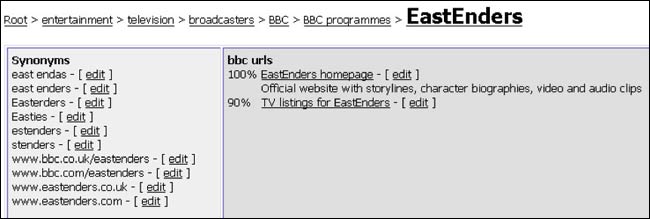
The “EastEnders” node in the BBC’s search taxonomy tool
My job then mutated slightly, and I began to specialise in search log analysis. It came about by accident. Tom Loosemore had been to Google, and been impressed by the real-time display of searches they had in their main office. He thought it would be good to do the same at the BBC Bush House reception. And so, with some very rough and hacky Perl, I wrote a script that would take the logfiles, strip naughty words out, and then display them in a news-ticker style on a webpage.
The important thing was that it really got me looking at the BBC’s search logs. Over the Christmas holiday in 2002 I hand-classified a sample of 20,000 search terms from a single day of search on the BBC website, and gave a presentation of my findings within the organisation. Crucially, I wrote the study up as an article on my then very young blog - “A day in the life of BBCi Search”. At the time there were not many case studies from big media companies on the use of their internal search tools, and so it was noticed. One of the people who linked to me was Louis Rosenfeld, and suddenly I realised that there were a few people out there interested in analysing search user behaviour.
Another step along my personal introduction to the world of IA was when I began to start reading some papers from chi2003. I’m not even sure how I stumbled across them, but it turned out that in one of the papers, James Kalbach had reviewed the BBC’s site search interface.
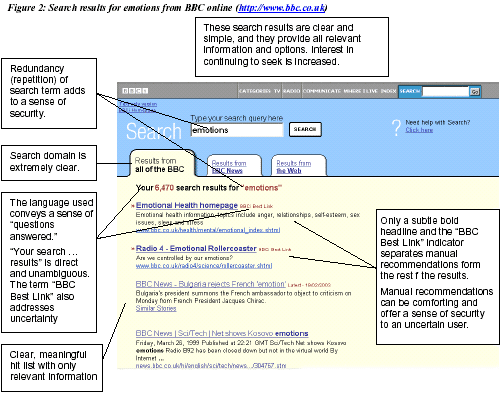
James Kalbach’s annotation of a BBCi Search results page from his 2003 CHI paper
This was another “Come as you are” moment for me. My academic background was the humanities - I studied History. My computer knowledge started with having a ZX Spectrum home computer and programming in BASIC when I was a kid. I knew you could study computer science and programming, but I had no idea that HCI existed as an area of study.
This is something, over time, that has become to frustrate me with our community. For some reason, because people decided that the Mosaic web browser was the most amazing new thing to be unleashed on the planet ever, we treat it as some cultural year zero for design. I came into the field with little related knowledge, but there is so much prior art in interface design, information design, typography, psychology and any other number of fields that apply to what we do as IAs and UX people, yet it feels like sometimes our reading lists don’t go back any further than “Don’t make me think” and the Polar Bear.
I’ve written a lot about the BBC search project on this blog and on the BBC website over the years. If you are interested in finding out more then I’d recommend reading:
“A day in the life of BBCi Search” - on currybetdotnet, March 2003
“Developing search at the BBC” - on the BBC Internet blog, November 2007
“History of web search at the BBC” - on currybetdotnet, March 2009
Next...
I left the BBC in 2005 to go freelance, and in the next part of this essay I’ll be looking at the things I learned working in a very different environment, for Sony in Austria.
[1] There is obviously something in this newspaper cuttings business. My colleague Karen Loasby at The Guardian also worked with me at the BBC for several years, and she also kept the clipping of her first BBC job advert [Return to article]
I remember the old days at uni, using AltaVista and Lycos for search when they first came on the scene. Nobody had heard of Google in those days. It's interesting how Google managed to so completely dominate the market, so much so that the word Google hs become a generic term for 'search'. But of course, everyone uses Google, it's fast an efficient. Do they have any real challengers. Not Bing anyway.