A day in the life of BBCi Search - part 1
A day in the life of BBCi Search - Introduction
Since BBCi launched in November 2001, the improved search offering has been collecting data on the way that BBC website users search both the BBC's website, and through the homepage Websearch, the whole wide web.
Given such a mass of data, the easiest way to aggregate and make sense of it has been to measure the search terms that are most popular. Indeed, the BBCi homepage has a panel displaying the three most popular search terms of the moment, and an editorial and taxonomy team at the BBC constantly monitor the searches gaining high volume in order to match the correct content to them.
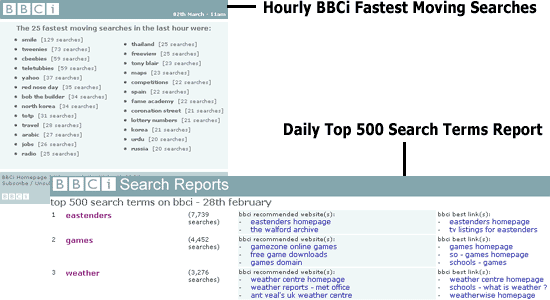
The team use reports that are generated hourly, daily and weekly to monitor the activity of the users. An hourly email alert identifies developing trends in the search terms, and specialist reports focus on trends within searches that have been generated specifically on the BBC News & BBC Sport sites. Daily lists of the most popular search terms from both the site as a whole, and the homepage websearch are generated, and weekly summaries focus on searches that originate in specific content areas of the site like Food or Cult TV.
However, it became clear that the searches that make the top 500 searches of the day are not necessarily representative of search behaviour as a whole. The majority of users on BBCi put something unique into the search box, and 80% of the users of the service put in search terms that never appear on any of the statistical reports, because they only happen once or twice during the course of a day.
I therefore wanted to find out what it was that this vast majority of users were actually doing on the service, and had to find a way of analysing their behaviour without relying on our existing model of aggregating popular search terms.
Methodology
One way to go about this was to isolate one individual day, and to analyse in depth the searches that had been made. The log files collected by the search service contain information not only on the terms used, but on the time the search took place, and the area of the site that the search originated from.
I chose Wednesday December 11th, as it was a weekday, during UK school terms, and there were no major breaking news stories or broadcast events to dominate results. A school term weekday is the most typical day of the year, and so the most typical use of the service - since the school calendar affects traffic to BBCi web services.
I also know from experience that search behaviour is affected by large breaking news stories, for example the loss of the space shuttle Columbia, or major UK broadcast events, like Test The Nation or the launch of BBC3.
To analyse the search terms I took 10 separate 6 minute samples from the log files, at different times of day, from 1am to 10pm. This was still too much information to classify, so I reduced the information to searches that had been made from the BBCi homepage at www.bbc.co.uk, and the searches that were made from the 404 error page. These are the most context neutral pages on the site, and reduced the amount of information I had to deal with down to a considerable but manageable 15,000 search terms.
I then took further 1 minute samples across the whole service to ensure that the data I was using was representative, and classified as a control sample an additional 3,000 search terms, to ensure that searches from the homepage and the 404 error page were representative of the usage of the service as a whole.
I measured the search activity on the day both in quantities using Perl scripts and spreadsheets, and by the hand-classification of individual search terms.
In part 2 of this article I will look at the UK and regional focus of the search terms.
I was searching for BBC news online and dropped over here. Its good to see the history of this site where we can't find in the site itself.
That must be a pretty mind numbing task looking through all the searches that have been made in a site as big as the BBC.
Glad its not me
That sounds like a pretty daunting and technical task. Was the data returned able to be put to use in any way to improve the search function?
Wow this is fantastic. I printed out the articles for future reading... I'm a big fan of the BBC and the insight as to how it works from the inside is really interesting.
I absolutely love the fastest moving searches.. Very neat option and good for statistics as well!
Looking into search patterns, conversions and what makes people tick (or rather click) for a couple of projects I'm involved with and although somewhat dated articles they still have many very valid points. Perhaps most importantly they underline the necessity of using today's many free and automated analytics tools with a healthy dose of human touch.