Adding 'Linked Data' to The Guardian's API
I've written a lot about 'Linked data' and the news industry both here and on Guardian.co.uk, and one of the things that has driven my interest in the topic is that when I first saw the 'Linked data' cloud diagram, I noticed the glaring omission of any of the UK's major news organisations.
Today, the Guardian's Open Platform Content API has taken a first step towards appearing in that diagram, by allowing users to query our data by ISBN numbers and MusicBrainz IDs.
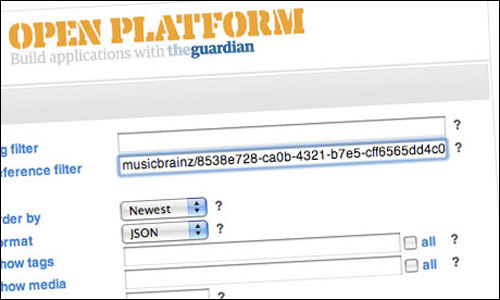
Anyone who has seen me talk about our domain model on Guardian.co.uk will know that we use tags to classify various properties about our content - the content type, the tone, the contributor who created it, and the topics covered. These tags can have an 'external reference' added to them, which point to a 'real world' thing represented by some data in another system, for example a film or match ID. ISBN number and MusicBrainz ID are two of these data types.
This isn't the 'semantic web' of huge top-down ontologies, and we aren't publishing RDFa or providing a SPARQL query endpoint. Nevertheless, I believe it is a significant step, and it is right for us to be providing as many hooks into accessing our content as possible, and making it relatively trivial for people to execute those queries programmatically.
Query the API for 'michael jackson' and you might get back articles featuring any number of Michael Jacksons. Query the API for f27ec8db-af05-4f36-916e-3d57f91ecf5e though, and you can be confident that you have content about the pop singer.
I've written a post for the Open Platform blog explaining a bit about it, and also helped with a short FAQ. Daithi O Crualaoich , the developer who has done the bulk of the technical work over the last month or so to make this happen will be talking about it tonight at our "Search at The Guardian" event in Kings Place, and has also blogged about the launch.
The APIs you use are way too technical for average users, compared to what Wordpress and Akismet is using. I guess further innovation for a much simpler linked data will evolved not any time soon.
linked data sounds useful but can it be placed on any site for any content? and how much tech expertise does it require?
In fairness Seth, you'd expect the low-level bit of an API to require some technical knowledge. What is important is that the API enables people to build things like the Guardian news feed Wordpress plugin, which means the content from the API can be re-used by anyone who can master the Wordpress control panel.
Well I kind of agree with Seth, the API is a bit too complicated for the average user, bu then again average users will not think about using the API, they will stick to wordpress and askimet..