Lack of hyperlinks exposes the news industry's legacy workflow systems
Last week, spurred on by a Patrick Smith blog post about linking, I wrote about how guardian.co.uk includes external and internal links on our site, and made some points about the user experience of external links on a news website.
Part of the reason that there is still a debate is due to the newspaper industry's unique legacy production systems and workflows. If you are generating 'web first' copy that includes a reference to a website address, whilst using a web CMS, then it is obvious to hit the 'link' button and add some HTML code to the page. If, on the other hand, you are in the middle of a desktop publishing workflow, optimised for hitting print deadlines, adding that kind of additional hypertext metadata doesn't seem quite so urgent.
It is when that flat copy is then re-purposed for the web or for apps that it becomes apparent the links should be there, and we see plenty of examples of that happening on news sites.
During the first couple of days of The Times paywall, people noted London Underground blogger Annie Mole spreading a photograph of an article in the paper that mentioned her blog. There were plenty of jokes about how this was going to be how people 'shared links' in the brave new world.
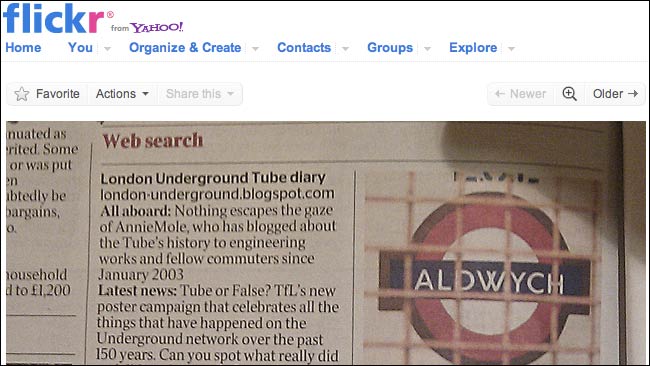
Even with access behind the paywall curtain though, a quick search for references to the Going Underground blog on the new Times site soon turned up articles specifically about links to websites, which did not include clickable hyperlinks.
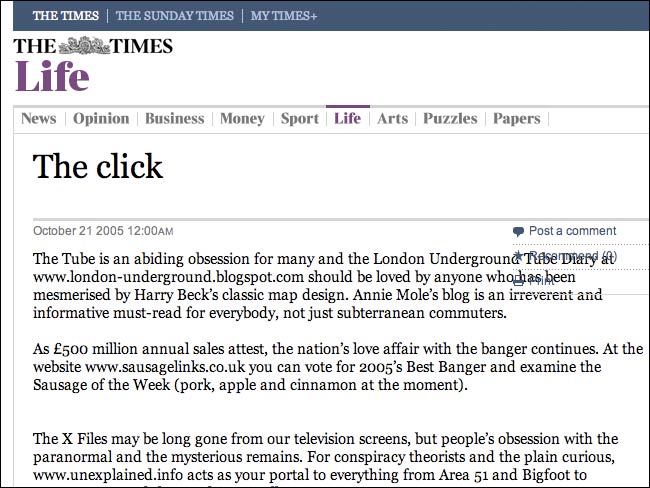
This example was first published in 2005, and you could be forgiven for thinking that in the intervening years, the age of crass shovelware had gone. Yet when I had my first look at news iPad apps I saw exactly the same phenomena on the New York Times app. Despite being re-purposed for a networked device, pieces that were specifically written about links to websites had the hyperlinks squeezed out of them during production.

I've no doubt you could point to examples of unlinked web addresses buried in the copy of thousands of articles by hundreds of papers around the web. In fact, in order to avoid pot/kettle/stones/glass houses comments, I've already found three recent examples on guardian.co.uk of unlinked URLs featuring www in the body copy. [1/2/3]
How to solve this?
One way, of course, is to shift the workflow in all of our newsrooms to think hyperlinks and digital first.
And the other way?
Erm...
It's also worth noting that some legacy - and even new - newsroom systems don't permit journalists to add inline links within stories. Instead of hitting a handy link button that will add HTML in a contextually sensible way, links in some web setups are formatted separately and have to be set up as independent floating sidebars, taking unnecessary amounts of time and effort, which in a print-first newsroom frequently just doesn't get done. Or in extreme cases the system simply doesn't permit them at all. This is the sharp end of the problems with the desktop publishing workflow - when taken to extremes they simply make it impossible to write well for the web.
It's relatively easy to find hyperlinks in text - assuming they start with "http" or "www".
Essentially, it's an automated search and replace.
There are lots of ways to do this. I use Matt Sanford's excellent library from
http://github.com/mzsanford/twitter-text-php/blob/master/src/Twitter/Autolink.php
Obviously just a first step, but there's really no excuse for not using an automated process to identify text that looks like www.*.(com|net|org) and turning that text into a hyperlink. Every email and twitter client out there can do it.
Ultimately though, composing in hypertext just makes more sense. It is much easier to remove the HTML metadata automatically for web-to-print translation than to add it automatically for print-to-web.
Actually, there are plenty of legitimate reasons why as a news organisation you might not automatically want to link to anything that looked like a web address - for example if you were writing about a site that had perpetrated a fraud, or the article was about malicious websites to avoid, why would you want to link to them? And you'd need an algorithm that was also able to tell when it should or shouldn't apply rel="nofollow" to the links it produced.
I agree with Martin, while it is easy to do searches and automatically link up text and turning them into hyperlinks, it might not be such a great idea for any organization especially news groups and papers as you could inadvertently link up to something you might not want to be associated with.
Wouldn't automating it force the author to think about it - some short tem cock-ups would result, but long-term benefits?
And in practice, surely most articles about malicious code etc don't actually list the full URL (I await the stack of examples otherwise)? Likewise, the number of nofollows required would be miniscule?
Why wouldn't you want to link to them? People who want to go there will go there anyway and be annoyed that it wasn't linked. People who don't want to go to the scary website won't go to the scary website. Or teach the software and the writers to distinguish between the 'name' "scarypuppyfraud.com" and the URL "www.scarypuppyfraud.com".
Also: the sooner people drop the idea that a link implies endorsement or association, the better. Screw nofollow, no one cares.
How about simply running the content through this regex? Problem solved.
I can't believe how long it's taking traditional media to "get with" the times, and embrace digital media by doing simple things like linking within articles. On the one hand, they complain about losing readers and yet they refuse to embrace the open source mentality of the rest of us.