London Linked Data meet up: Notes and take-away quotes - part 2
This week I've posted quite a bit about the Linked Data London meet-up that I attended in Hammersmith last week. As well as a two part transcript of my contribution to a panel about 'linked data and the future of journalism', yesterday I published the first part of a set of notes and take-away quotes from the event. Here are some more.

'About a third of a newspaper is data' - Andrew Walkingshaw
Either he is stalking me, or I am stalking him, but one way or another I think that the last three events I have spoken at have also featured Andrew Walkingshaw from Timetric. At the Linked Data event he gave a more technically focussed presentation about the architecture of Timetric's service than I've seen before, and appealed for help and information from the 'Linked Data' community about making it more user-friendly for them.
Andrew argued that information doesn't always want to be free, sometimes it wants to be lunch, and that data providers often expect to be paid for their work. He had some great slides about the use of data within news publishing, arguing that about a third of the average newspaper consists directly of published data. Some of those, like football fixtures, are tightly controlled by licenses, and generate revenue for the football leagues in the UK.

He also made a telling point around the broader issue of classifying news. "You can't predict what will be news", and therefore you can't define your schema up-front. A classic example we always use within The Guardian is Allen Stanford. The initial articles we published about him were slotted into the 'Sport' section as they were universally about the cricket tournaments that he was bankrolling. However, by the early part of 2009, the thrust of any story written about Sir Allen had changed to be about the issue of the legitimacy of his financial activities. No longer did the 'Allen Stanford' keyword fit neatly into the taxonomy sphere of 'Sport'. Instead, it was now 'World News'. We couldn't have known that when journalists were initially filing stories about his plans for a $20m Twenty 20 game in February 2008.
Linked Data in healthcare
Jun Zhao presented a medical application of semantic data. She is part of a research project looking at drug discovery, and linking 'western drugs' with alternative medicines. By merging several databases of knowledge about the chemical make-up of effective solutions, they hope to predict others, and identify natural remedies with the same chemical constitution. One voice from the floor hoped that a structured data approach might be able to debunk homeopathy.
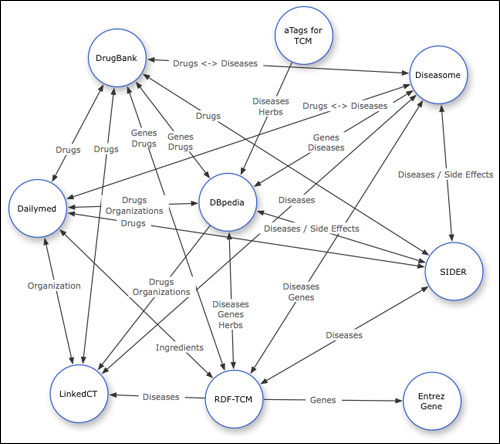
Personally I was reminded of Dr Ian Lipkin's presentation at the Activate Summit earlier this year. He demonstrated how a shared data approach was helping labs around the globe react faster to outbreaks of infectious diseases.
The omnipresence of the BBC
A significant number of presentations during the day were from BBC staff, and even a couple that weren't made use of BBC data as an example source. I have long been aware of the work that the team behind BBC /programmes have been doing in providing permanent URIs for broadcast material. The presentations did introduce me to some new things though, especially in the sphere of Nature. Tom Scott and Yves Raimond showed that the BBC now has permanent URIs for animal classes, habitats and adaptations.
It has come a long way from my day when the Wildfacts 'database' consisted of a CSV file that used to get spun into HTML by a Perl cron job, and barely registered in search engines due to the lack of cross-linking between entries.
"The DJ's role was only there,
to fill in space between the songs
that talk of love and other things,
as if they really mattered.
Automatic stations came,
and sent them all away." - 'WXJL Tonight' by The Human League
As well as the Nature examples, the BBC has also done a lot of work with linking music data. They demoed a playlist that automatically generated its own track intros and outros, including a speech synthesizer reading snippets of data about artists that had been retrieved using linked data and the unique URI of each track and artist. Well, that is what I think it did, anyway. It won't quite replace DJs yet, but it looked like they were getting there...
One thing did leap out at me from the BBC being featured in so many demos during the day. It does suggest that the corporation is leading in this area in the UK at the moment, with Government data being the other major hope of linked data publishing. That also suggests that a lot of this work at the moment falls into the realm of 'theoretically nice to do', but too time-consuming and with unproven worth to the businesses outside of public sector organisations.
The demand from the audience, of course, was that the BBC should do more. One question during Michael Smethurst and Matthew Wood's session asked 'What is stopping you from implementing more of this?'. After a short pause the answer came back 'the high-ups would like stuff to be broadly aligned to a product strategy'. I'm not sure the rest of us have the luxury of the word 'broadly'.
And finally...
You can find links to a lot of the talks from the day on this blog post by co-organiser Silver Oliver. If all this talk on the blog over the last couple of days about 'Linked Data', 'the web of data' and the 'semantic web' has been leaving you feeling a little perplexed, then help is at hand. Michael Smethurst and Yves Raimond at the BBC have produced a fantastic set of introductory slides to this whole area, which I think is worth looking at by anyone with any interest in the future of how the Internet is shaped.
Read more of my articles about notes and quotes from media and web events and the future of news
I have no idea who's stalking who, but I was sorry to have to leave before you spoke! I'll nick that Allen Stanford example if that's OK with you, it's terrific...
It was a bit of a different crowd to the other events, so the talk was a bit different too. Still, it's an interesting field, and I reckon it's pretty hard to try to be a socially-conscious technologist these days without caring a little too much about data...