ACAP - flawed and broken from the start?
Last week a consortium of online publishers announced ACAP - Automated Content Access Protocol - a new 'standard' for instructing search engines how to index content. For me there were three immediate major flaws apparent.
It isn't user centred
The entire thrust of ACAP seems to be to control the way in which newspaper or publisher content is indexed and displayed by search engines, in an attempt to strictly define the commercial parameters of that relationship. On the ACAP site I didn't see anything that explained to me why this would currently be a good thing for end users. It seems like a weak electronic online DRM - with the vague promise that in the future more 'stuff' will be published, precisely because you can do less with it.
Take for example the idea that publishers can direct what type of excerpt from an article can be displayed in search results, and how long that excerpt should be.
Well, most search engines now display an excerpt that is context sensitive. If the user has been searching for images, or the result is a video clip, they get SERPS with images and clip thumbnails in them. Mostly, though, they get a text snippet that includes the words they searched for. This helps a user judge whether a link is worth clicking or not.
What ACAP suggests is that it is up to the publisher whether a search enigne can display a contextual snippet or not - meaning a potentially inconsistent user experience within the search engine results for the end user. If their search results include an ACAP-enabled site that requires a specific excerpt, and their keywords fall outside that excerpt, they will not see the words highlighted in context on that one result.
ACAP could also be potentially restrictive on the development of search user experience design. The ACAP dictionary allows for the presentation of 'Content item thumbnail' or 'Publisher thumbnail'. The spec also appears to cater for specifying on a <div> by <div> or HTML element basis what search engines can index and display - by hijacking the class attribute in the HTML specification.
How does that apply to Snap's full page preview? I didn't see anything in the specification that addressed, for example, whether it would be OK for Snap to reproduce whole visual page snapshots when delivering search results. Is a thumbnail preview of a page automatically forbidden unless specified otherwise? If a publisher incuded content that crawlers were denied access to by using an embedded HTML tag, does that consequently prohibit Snap from previewing the whole page?
The thinking behind ACAP seems to have been solely focussed on influencing the existing interface of Google, Yahoo! and news aggregators, without considering the impact on users of other, more visual, search engines on the market, or the potential for future user-experience developments.
It isn't technically sound
When I say technically sound, I don't mean it will actually break things, but it doesn't appear to have a technically robust background to it.
Well, I say it won't actually break things, but the technical framework document itself admits that the specification includes:
"extensions for which there are possible security vulnerability or other issues in their implementation on the web crawler side, such as creating possible new opportunities for cloaking or Denial of Service attack."
I've no doubt that there has been technical input into the specification. It certainly doesn't seem, though, to have been open to the round-robin peer review that the wider Internet community would expect if you were introducing a major new protocol you effectively intended to replace robots.txt. ACAP attempts to redefine the relationship between all content publishers and all search engines - by default we are all affected. On November 29th this site, and the scripts that power Chipwrapper, by default became ACAP non-compliant.
The vast majority of technical standards on the web are published in HTML, with plenty of named anchors. The technical framework document for ACAP itself is a PDF document, which makes it impossible to link or reference sub-sections of the document. Amusingly, it also makes it harder for search engines to index the content.
Furthermore, in order to read it, it requires a user to have plug-ins installed to their browser. The PDF format isn't without accessibility issues unless correctly structured - although as I've recently seen, accessibility doesn't seem to be something that the newspaper industry is overly bothered about online.
Finally, this seems to me to be a case of protocol wheel-reinvention. I don't yet see anything at a page indexing level in the ACAP protocol that couldn't be achieved by the proper implementation of the existing robots.txt protocol, along with issuing the correct cache and response code headers with pages.
If you want content indexed or not indexed, robots.txt caters for that. You can instruct search engines on caching through META tags and HTML header responses. If you only want search engines to index a small amount of your content, then you can already publish that in a crawlable place, and link through to the full article specified as 'noindex'.
The ACAP website tools don't work
UPDATE - 21/01/08: In the comments, Alex points out that this bug in Firefox does exist, and that the HTML gumph is added by Internet Explorer, not poor coding. Which means my gripe is not, as he says, with "the poor developer who wrote the perl script", but with the business process that allowed it to go live as working, when it clearly doesn't do the job.
The ACAP website encourages users to implement the ACAP protocol in advance of it being adopted by search engines, in order to show the mainstream support for such an idea. The Times web site has already done so. ACAP provide a tool for converting your robots.txt file to one that includes the original robots.txt instructions alongside the more explicit and granular ACAP instructions. A user is asked to upload their robots.txt file, and then save the resulting output.
The ACAP site states that:
Note that, due to a known bug in Mozilla Firefox, you cannot save it directly from the browser window, but must copy the content of the window to the clipboard, paste into a blank text document (e.g. in Notepad) and save from the document editor.
This piqued my interest. I was unaware that there was a 'known bug in Mozilla Firefox' that prevented it saving a text file as a text file. I was going to make a cheap shot at the way that was phrased, as it clearly should have been 'there is a known bug in our script which affects Mozilla Firefox'.
I thought though that I ought to check it in Internet Explorer first - and found that the ACAP tool didn't work in that browser either.
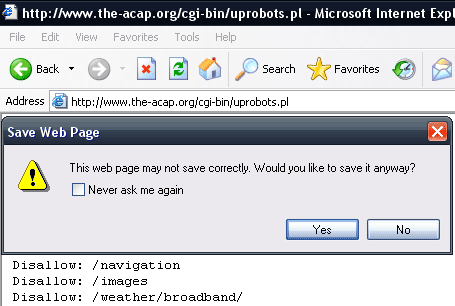
When you save the output of the conversion tool using Internet Explorer, you get a text file that includes a HTML 4.0 Transitional DOCTYPE declaration and some <PRE> tags before and after what should actually be the new plain text hybrid robots.txt/ACAP file.
So just to re-cap - the consortium behind ACAP are proposing a new technical standard that unilaterally extends HTML and robots.txt, and wants to redefine the machine-to-machine relationship between every web publisher and every search engine or content aggregator. According to the ACAP FAQ: "The primary drivers of ACAP are the World Association of Newspapers (WAN), the European Publishers Council (EPC) and the International Publishers Association (IPA)"
And yet it appears that between them they haven't been able to hire a Perl developer who can write a CGI script that outputs plain text...?
How will this iniative affect the world's top search engines like Google, Yahoo!, MSN, Ask et al? Well, altogether it reminds me of the ludicrous futility of the '#privacy' campaign. I'll draw your attention to this section of the ACAP FAQ:
14) Have you discussed this with the search engines?
Major search engines are engaged in the project. Exalead, the world's fourth largest search engine has been a full participant in the project.
Exalead eh? I guess that must be 'fourth biggest' in index size or something - because it sure doesn't seem to be by market share.
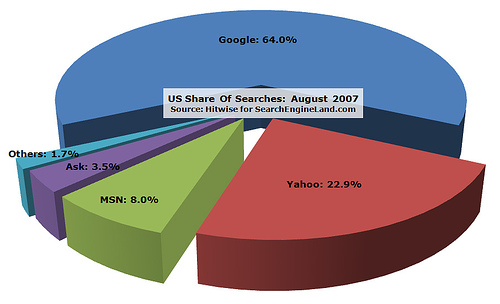
Well if Exalead are fans, then it must be good. Now if someone could just tell me who on earth they are, it will make me even more convinced!
Martin
> I was unaware that there was a 'known bug in Mozilla Firefox'
> that prevented it saving a text file as a text file
then check out:
https://bugzilla.mozilla.org/show_bug.cgi?id=300032
And MSIE is correct in warning that the file "may not save correctly" as it *itself* is adding the HTML page furniture.
What you're seeing is mainstream browser behaviour in the face of plain text sent with a "text/plain" MIME type, so I suggest you grumble instead about that, rather than the poor developer who wrote the perl script ...
[Full disclosure: I am that developer]
- Alex.
Thanks for that Alex, and I have edited the post accordingly
Hi there, Martin.
Automated Content Access Protocol - this MSN, Yahoo or only google? So just to re-cap - the consortium behind ACAP are proposing a new technical standard that unilaterally extends HTML and robots.txt, and wants to redefine the machine-to-machine relationship between every web publisher and every search engine or content aggregator?