'Linked Data and the future of journalism' - part 1
Last week I appeared on a panel chaired by Paul Bradshaw at the London Linked Data meet-up, discussing the future of data and journalism with John O'Donovan, Dan Brickley and Leigh Dodds. I made a very rough audio recoding of the session, so I've been able to put together a transcript of what I said in response to a wide-ranging set of questions. I should add that, as ever, these comments express my own views, and are not the views of Guardian News & Media.

Martin Belam on 'Linked Data and the future of journalism'
One of the things that is interesting to me is that as a lot of papers are preparing to put paywalls up and shutter their content behind them, The Guardian has done exactly the opposite by building the Open Platform, and allowing anybody with an API key to re-use our content. You can get the full text of our website archive marked-up in XML, JSON and ATOM, and there are pre-existing client libraries for Python, Ruby, PHP, Java and Perl amongst others.
There is a real tension there between that, and organisations that are wanting to charge money for news. You could conclude that between ourselves and News International, one of us must be wrong. However, for a start, The Guardian is structured differently from other national newspapers. It is owned by a trust whose mission is to protect the paper's journalism, and the business is 'profit-seeking' rather than having to be 'profit-making'.
Matt McAlister gives an example of where the Open Platform fits into this, suggesting that, in the future, two bloggers in Brazil having an argument about the carbon footprint of a company can come to The Guardian's Data Store to get their evidence, republish some articles to support their positions, and all of it will be branded and attributed to The Guardian, and we need never know that it has happened.
That does mean that we are very conscious now of how we structure and mark-up our information. For example, if I create a new section on guardian.co.uk called "ZZZ - Martin's test site - don't publish here" and I don't distribute the URL, then it should stay relatively private. Well, until Google picked it up from our sitemaps I suppose. However, my sandbox would certainly be instantly exposed to anyone searching through the API. As we are building products and services, we often stop and think "OK, how is this content or data structure going to look when it appears in the API?".
News organisations have generally relied on one business model, advertising. I think now we will all have to move to a more hybrid set of business models, and The Guardian sees potential to drive not just reach and influence, but revenue through distributing content in this way, though it would just be one strand of potential revenue. I rather like this analogy from David Cohn: news organisations have just jumped off the Titanic as it sinks. In the water there is a lot of loose timber. Clinging to one piece of timber - or one business model - will not save you. However, lashing together several bits of wood to make a life-raft might.
When we talk about 'Linked Data' and journalism I think there are two elements. Firstly, how do you publish the end product - the news - in machine readable formats that allow for re-use and semantic understanding of content. But secondly, there is how 'Linked Data' can be utilised as a research tool to help professional and non-professional journalists unearth and tell stories.
I did a presentation at the News Innovation Unconference where I advocated 'journalism centred design'. Not 'journalist centred design' I hasten to add, that would simply be a big photo of the journalist and a byline bigger than the headlines.
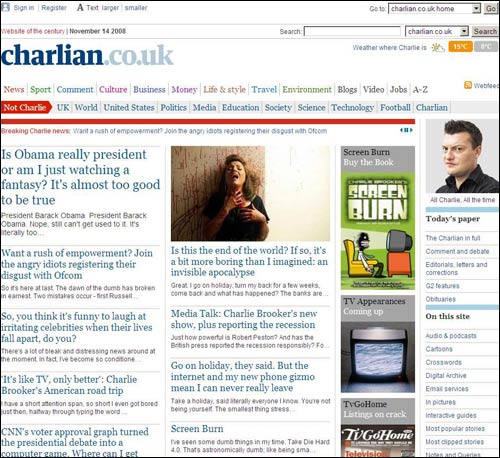
I believe we can learn from the industrial methodology of time and motion studies on production lines to develop 'lean manufacturing'. The requirements of a journalist working on the film or music review desk, and those working on the financial or foreign news desk are quite different, yet almost all news organisations will sit them down in front of exactly the same CMS screen. For me, the key to making 'Linked Data' work for journalism is about building tools that allows people to exploit this data when they are researching stories, it shouldn't just be about adding some fancy metadata to news websites.
Next...
Paul Bradshaw wrote up an excellent overview of the session on the Online Journalism Blog, which includes a video clip of some of it. Tomorrow, on currybetdotnet, I'll be continuing my rough transcript of what I said at the event.
Read more of my articles about Martin Belam talks and presentations and the future of news
Thanks for the great write-up, Martin -- and sorry about dissing your XML skills on twitter during the session...!
I just wanted to say that my favourite quote from your talk was
"The requirements of a journalist working on the film or music review desk, and those working on the financial or foreign news desk are quite different, yet almost all news organisations will sit them down in front of exactly the same CMS screen."
that's something many people haven't clocked yet, and hopefully will be a big area for innovation in CMS design over the next few years...
This idea interests me, especially when thinking about how bloggers can reap the benefit of linked data. What makes blogging to become popular is when bloggers connect each other. Initially, it's between people behind the blog. But eventually, it's going to be about connecting ideas and resources that weren't previously linked. Current technology has lowered the cost of publishing as well as establishing standards for the first issue you mention "publishing the end product". So the upcoming trend should be about how to collaborate better. It's more than putting FriendFeed discussion in a blog, it's about utilizing linked data in certain context, making blogger -the non-professional journalist- be able to develop more profound knowledge.
I rather like the Titanic metaphor as well. I think it has the added benefit of suggesting that the dominance of any one business model or even business philosophy/goal is dangerous and unhealthy for a discipline. It will ultimately be a good thing for journalism to be forced to rethink both its means of survival but also its purpose. It seems to me to have always been dangerous and unhealthy for journalism to be little more than a vehicle for advertising. If I understand your "journalism centered design" idea I rather think I agree. The format and structure of how something is presented should absolutely be specific to the type of information being offered and the community being served. There are some great interviews and discussions about issues facing the future of journalism at www.ourblook.com/topic/future_of_journalism.html which I have found useful on these subjects. You might be interested as well.