From Afghanistan to Zygons - Data journalism at The Guardian
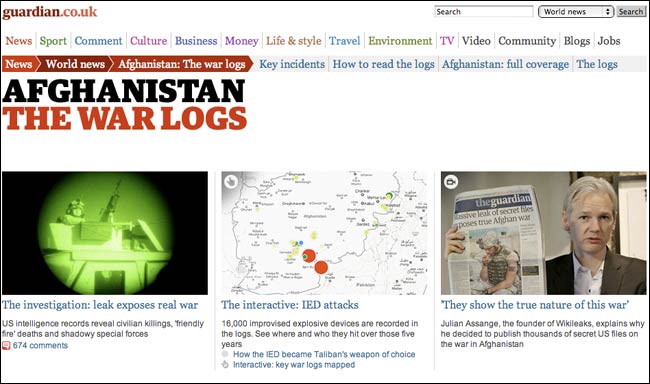
Following the publication of the Afghan War Logs, there has been a surge of interest in the way that The Guardian & The Observer do datajournalism. Simon Rogers wrote a blog post at the end of July outlining how our datajournalism operation worked to process the information from Wikleaks.
A couple of weeks previously, it was a rather more frivolous topic that was attracting the most ever community engagement on the Data Blog. An attempt to catalogue every Doctor Who villain ever in a single spreadsheet sparked a massive series of comments, and it took over Simon Rogers' life.
Jonathan Stray recently interviewed Simon about data journalism for the Nieman Journalism Lab website, and you can see a 25 minute video of the encounter, which features him talking about Doctor Who amongst other rather more important datasets, including our World Government data search.
With all this interest, and the recent increase in the number of datasets offered by our search engine, I finally finished off a blog post for The Guardian that I started drafting back in December 2009. It looks at my contribution to the project, as I sketched and then wireframed up the Information Architecture behind the World Government Data search.


“Who’s Who? The Resurrection of the Doctor” charts how the Guardian has covered Doctor Who since it was revived in 2005. If features interviews with Christopher Eccleston, David Tennant, Matt Smith and the men in charge of the show's fortunes: Russell T. Davies and Steven Moffat. It also includes interviews with a host of other Doctor Who actors including Billie Piper, Freema Agyeman, John Barrowman and writers including Neil Gaiman and Mark Gatiss. There are contributions from legendary author Michael Moorcock, Seventh Doctor Sylvester McCoy, and specially commissioned illustrations from Jamie Lenman.
“Who’s Who? The Resurrection of the Doctor” - £2.99 for Kindle & iBooks.
In an age where we are almost buried with information, this new way of doing journalism seems to be the onyl way that folks in the industry can stay abreast ofd things, while being able to provide a summary of events to their readers without overwhelming them. Very intresting to see how the other side does things.
Surely data journalism must include gathering data on your own. As a reflection of the state of contemporary data journalism practice, this document might be forgiven for excluding it; but I would hope that any book used for instruction or direction would try to improve the field. Otherwise, data journalists are relying on data providers to do most of the investigating for them.