The tyranny of chronology: Part 4 - Meaningful metadata and our missing librarians
This is the fourth in a series of posts based on the presentation given by Martin Belam at the 'News Innovation' unconference in London on July 10th 2009. You can find part one here.
Meaningful metadata
In yesterday's part of this series, I looked at how news stories might be disaggregated further, if only machines could understand more about human language. I suggested that one way of teaching systems about content in to use more of the 'm' word - metadata.
Incidentally, in preparing this talk I thought it would be great to have an image to illustrate 'metadata' - and this is the selection of images that Google presented me with. Have you ever seen a less visually appealing image search results page?
Nevertheless, whilst it might be dull to visualise, I think sexier metadata is the key to moving our news content out of the space-confined chronologically ordered silos we tend to publish them in today.
The metadata of the Anglo-Saxon Chronicle can be a little bit patchy, but most stories contain year, person, person type, location and event. In a digital era, think of the richness we could be adding to all of our stories, and the content and journalism that could be generated as a result.
If you thought the previous set of metadata diagrams was dry, then you probably are not going to be impressed with a picture of noun declension tables for Latin and Greek, but I think there is something instructive in thinking about our news language in this way.
We need metadata that incorporates the genitive and accusative cases, and we want to know whether someone is passive or active in a story. When we add location data to news we want to know whether it is because the event happened there, or whether the event had impact there. We need to be able to vary the range of location data, to tell our machines whether a story has global significance or hyper-local relevance.
We are making progress in this area - but sometimes the tools we are using are still very crude. This example isn't to specifically have a go at the Daily Mail, as I think their 'explore' pages around people and places are an interesting innovation from them on their site. By chance though, as I was putting this presentation together, they seemed to have the worst public facing example of the point I am trying to make.
On the 9th June, the main story on their 'Gordon Brown' person page was a review of a camper-van.
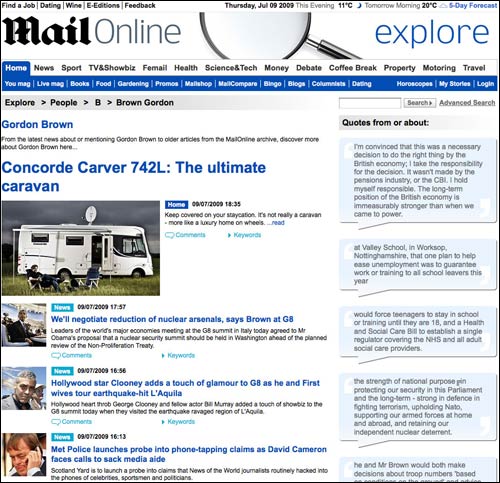
The review mentioned Gordon Brown in passing in the opening paragraph:
"These days in Britain there are a few people - just a few, mind - who are busier than ever. Gordon Brown's therapist is worked off his feet. We all know how busy MPs' accountants have been - almost as busy as their gardeners, builders, decorators and moat cleaners."
As a result, it had been, automatically I would have guessed, tagged 'Gordon Brown'. Since the page displays the stories in, and I apologise for sounding like a broken record here, reverse chronological order, it occupied the prime slot. The camper van review had been filed about half-hour after a report on what the British Prime Minister had said at the G8 summit, and due to the deference paid to chronological order, it was displayed as the most important story.
Where are our librarians?

One of the other problems that I think we experience is that we used to have librarians, and now we have content management systems. However, a lot of the time, we simply treat them as content creation systems or content publishing systems. Whenever we scope one out, or enter a deal with a vendor, we pay a lot of attention to how quickly we can publish something with a CMS. As an industry, we often pay scant attention to how we manage that content afterwards.

Newspaper and media librarians used to carefully curate cuttings files. If an article was relevant for three topics they would copy it and place it in three folders. Cuttings files would be periodically re-examined and the contents trimmed to the really important stuff. The Association of UK Media Librarians recently decided that there were not enough of them left to keep the organisation viable.
It seems simply crazy to me that at a time when we are producing more media content than ever before, we are employing less and less people to expertly curate it - leaving it instead to machines and systems that we have not trained properly to deal with the complexity and nuances of our news 'language'.
Next...
Tomorrow, in the final part of this series, I'll be advocating that we need to adopt an approach of 'journalism centred design' in our systems and processes.
I couldn't agree more. I think part of the problem is that people are more focussed on SEO than visitor experience, which is ultimately self-defeating.
I have been meaning to write an article about online content curation for ages. I honestly believe the way forward is to set up an agency, whether it is non-profit, public or government run, to keep internet content better regulated.
And don't even get me started on Wikipedia.
I don't remember who said it but I loved the comment that;
"The internet is like the worlds biggest library, where someone has thrown all the books on the floor"
There is an amazing amount of information out there, but for people to be able to locate it, it's the spiders that pages have to appeal to, and I agree with you, this doesn't often convert to being people friendly.