Web search at the BBC: Part 9 - The end is the beginning is the end
I've been writing a series of posts looking at my memories of the development of the BBC's now discontinued web search service.
By 2004, I'd moved on to other things within the BBC. The BBC homepage was re-designed again, this time to reflect another re-brand, from BBCi to BBC.co.uk.
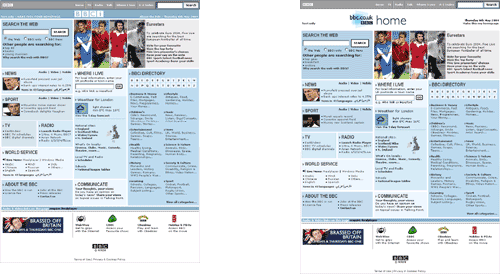
At the same time the search box was changed from defaulting to web search to defaulting to site search, with the marketing-driven label: "Explore more than 2 million amazing BBC pages". The shift away from promoting the homepage as a place to search the web could not have been sign-posted any more clearly.
This was, realistically, the end of the BBC making any serious attempt to provide a competing public service web search offering. The only way to access the web search was to perform a search, ignore the results, and hit the 'web' tab. It was certainly unlikely to shift people from using Google as a reflex.

After that particular re-brand, I ended up looked after the technical production and product development side of the page for 15 months or so. Whilst on my watch I saw the value of the page as a news portal, rather than a search hub, demonstrated with the reaction to the July 2005 suicide bombings of London's transport network.

There was no longer any kind of senior management push towards promoting web search via the homepage. Instead, efforts had long been more focussed on delivering things like an audio and video search of BBC content to users, or for delivering a specialist search aimed at children.
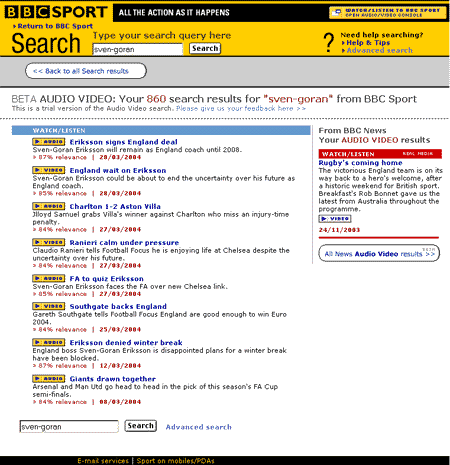
The first significant interface overhaul of the BBC's overall search service for 4 years took place in 2006. By then I had left the BBC, and indeed left the UK, but at the time I posted a series of reviews of the new interface here on currybetdotnet.
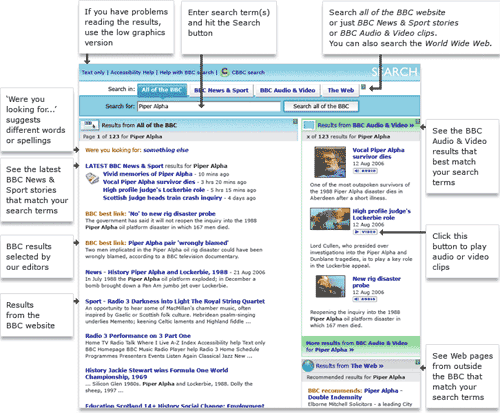
The most important development was much tighter integration of content into the main index. At the time, Daniel Mermelstein, who was head of search products at the BBC News website said of the old tabbed divisions of content:
"As a user experience that was a bit odd because people do not tend to divide it that way. What exact departmental silo it comes from is irrelevant."
In late 2007 I was commissioned by the BBC Internet Blog to write some pieces to commemorate the 'official' 10th anniversary of the BBC website. As well as covering the rise of interactivity, a brief history of Doctor Who on the web, and herding cats the information architecture of bbc.co.uk, I also wrote two posts about the development of the BBC search engine.
The BBC is now planning to invest the time and money saved by no longer providing web search by increasing the coverage of their 'Topic' pages, and improving external linking, a subject on which the BBC has been much castigated over the years. In Seetha Kumar's words when she announced the closure of web search:
"We'd do far better to concentrate on making our own BBC website search as good as it can be, for example by developing our topics proposition and improving the way we point users to other related content around and off the site. To be honest, there is a lot we can do to provide users with a range of editorially selected links to other high quality sites in the UK and elsewhere. There is a huge number of excellent links across the site. The problem is that these links can be a bit buried away. So we need to bring all our links into a single database so that they can be presented to users in a wider range of contexts across BBC Online"
Both of these things are an evolution of ideas that the search team worked on back in my days at the BBC.
BBC iPages
The iPages project was the pre-cursor to the current incarnation of topics, which didn't get much beyond the rough prototype stage. I went to several product development meetings about it at the time. The idea was to cover people, places, programmes and subjects with one encyclopedic page that linked around to the rest of the BBC's content.
A major stumbling block was that, at that point, the BBC simply didn't have the majority of their web content in modular chunks that had sufficient metadata around them to enable their re-use. Without PiPs or iPlayers or /programmes, there were not even single pages you could point at for the majority of BBC brands, let alone external 'topics' and 'concepts'.
Another problem was that there also needed to be judgement calls about which BBC department 'owned' an individual iPage. "Climate change" was a classic example, where BBC News, the weather people, and the science department could all put forward a credible claim to be the ultimate BBC arbiter on that particular subject.
Central link repository
A second project mooted amongst the BBC Search team which never got off the ground was the concept of a 'central links repository'. The BBC's first attempt to get together a directory or reliable web links, WebGuide, floundered on the issue of scalability, but the concept of being a "trusted guide to the web" for the online British population was one that was taken seriously.
The idea of the link repository was that a central team should maintain a database of reliable and editorially sound links. Other departments around the BBC could then use this repository as the basis of their link research, and hook into it to provide links on their pages.
This would mean that, for example, links to the biography of President George W. Bush from all over the BBC would point to the same place in the repository database. Then, as happened earlier this year, if the White House website changed, and the George W. Bush URL was moved, it would only have to be changed once in the repository. That change would then be reflected across the BBC site.
It is a very powerful idea - a sort of internal bit.ly - which was hampered by the BBC's technical architecture of the time. When we were discussing the idea, the BBC site was almost exclusively built by disjointed systems in Perl producing static HTML pages, which didn't lend themselves to this kind of dynamic re-writing of content across the whole site.
Conclusions
I don't think the wider BBC - the one that runs television and radio channels and not websites - ever got to grips with the idea of the Corporation also providing web search.
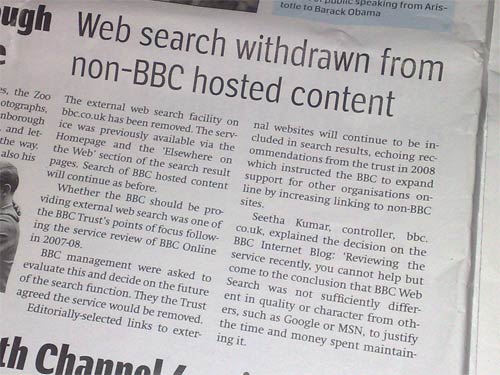
This was epitomised by the Ariel headline that greeted the closure of the service. You and I might know it as the 'World Wide Web', but what we are actually using when we aren't on the BBC site is 'non-BBC hosted content'.
"Web search withdrawn from non-BBC hosted content"
In retrospect, it all seems like a very odd idea. I mean, why would you think to go for the BBC for web search?
But I still think it may well be looked as equally odd in the future that, within a few years of the Internet gaining mainstream traction, the UK decided that on the basis of a (mostly) shared common language, we didn't need any public service way of navigating the Internet.
Or, indeed, unlike France or Germany, any commercially funded way of searching the Internet that didn't see all of the advertising revenue flow straight across the Atlantic.
![]() You can now download the entire 'Web search at the BBC' series in one print friendly PDF
You can now download the entire 'Web search at the BBC' series in one print friendly PDF
Credits
This series dedicated to the memory of Katherine Everett.
With thanks to: Jennifer Rigby, Julie Rowbotham, Matthew McDonnell, Pidge Hendrie, Anne Scott, Karen Loasby, Gaynor Burns, Liz Winthrop, Chris Binks, Adrian Gordon, Mark Hewis, Iain Loasby, Murray Walker, Lee Harker, Darren Shukri, Andrew Bowden, Dominic Tootell, Nicola Hancox, Penny Harris, Emily Clarke, Matt Jones, Tim Bleasdale, Phil Barrett (Flow Interactive), Vincent Helyar & Kate Taylor (Serco), Tom Loosemore, Jem Stone and Tony Ageh.