"People, Places, Subjects" - BBC Topic and Guardian keyword pages: Part 5
I've been writing a series of blog posts looking at the BBC's new beta test of 'Topic' aggregation pages, and comparing them to the similar pages offered by The Guardian, who index their stories by keyword. So far I've looked at how the pages compare to the BBC's search results, at their URL structure, the availability of RSS, the type of classification used, and the external links that feature on the pages.
Gathering feedback
Like all good BBC Beta tests, the BBC are collating feedback on the user response - my team used to do much the same whenever we re-jigged the homepage for a bit. There is a good amount of free-text entry for users to put their point across, and also a couple of tick-box questions and ratings.
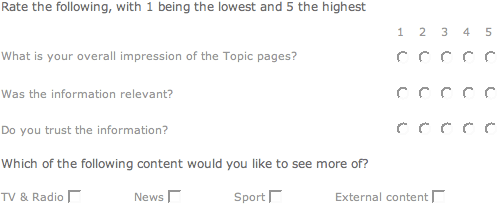
I'm sure Professor Monck will be horrified to see the mainstream media's obsession with 'trust' manifest itself in the metrics for measuring the 'beta'. Myself I was surprised at the limited options for what the user wanted to see more of - is the Internet really divided into the four options BBC TV & Radio, BBC News, BBC Sport and 'the rest of the web'?
'Topics' are a product
So, whilst there is a lot of similarity between the Guardian's keyword-based index pages, and the BBC's new Topics project, there is one very fundamental difference, which I think is quite symbolic of the difference between the two organisations.
The BBC have very clearly defined Topic pages as a product in their own right. They have a homepage, which presumably means they have someone to pick which topics are going to be featured in the picture promo space. Once they cover more than 60-odd topics they will also presumably need sub-index pages for 'people' and 'places', and an editorial pick over which links appear in the front-page directory. All of these things take additional resources.
By contrast, the Guardian's keyword indexes are not a 'product', they are more of a 'by-product' of the journalistic process - one that has been woven into content production process. The tagging of stories during publishing enables these automated aggregation indexes to be built. Yes, some of the pages have "Editor's picks" on them, but these are the exception. Any keyword page can be 'managed' by hand if it suddenly becomes ultra-topical, but the thrust of the 'keyword indexes' is to reduce the editorial overhead of managing index pages across a variety of topics. It is telling that unlike bbc.co.uk/topics, The Guardian has no top-level URL guardian.co.uk/keywords or guardian.co.uk/concepts or guardian.co.uk/themes, nor is it actively seeking feedback from users to suggest new 'keywords' to cover.
Conclusions
Both projects are fulfilling slightly different purposes for their parent organisations.
The BBC's Topic pages are in some ways papering over the organisational cracks that sees competing departments having a vested interest in their own sites dedicated to BBC-wide concepts and people like 'Jonathan Ross' (TV & Radio), 'Climate Change' (News, Weather, Factual) and 'David Beckham' (Sport & Entertainment). Topics put a user-friendly front page on departmental conflict.
The Guardian, meanwhile, is trying to use keywords as a way of making editorial selection 'go further'. They can cover a wider range of 'topics' using the same number of journalists and editors, just by virtue of getting the stories tagged correctly as they go through the CMS publishing process.
I think the end result for both organisations is beneficial, and should be good for users too.
Oh, and I don't think either company has missed a trick in spotting how good these pages might be search engines...
Hi Martin - I've enjoyed these articles, and blogged about them here.