BBC Complaints site in RSS
So I've mentioned before that the BBC has launched a new Complaints site. From my point of view the most important thing over the next couple of months is to monitor how much mail the BBC receives, and how much publishing is done on the site, which is acting as a central hub for official responses. Both of those will give me a good idea of how likely the site is to impact on the resources I have available to work on it, and, to be honest, I'm very interested in how the BBC reacts as a corporate entity to having this new channel to communicate with the audience.
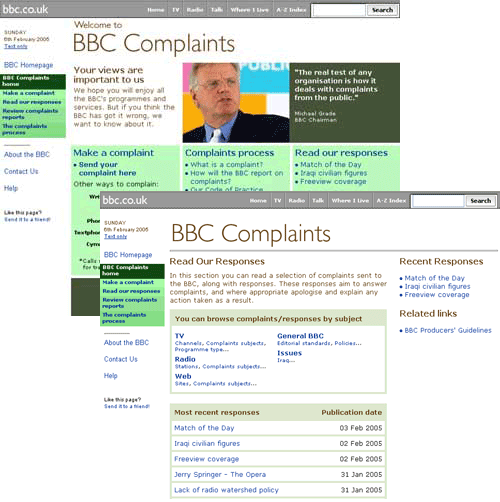
Being a busy and impatient person I really didn't want to have to check the site every day to see if a new response has been published. At the moment the BBC does not habitually publish on the live site RSS feeds of content, even when they have been generated by a mini-CPS that could do such a thing. So I've written my own script to scrape the site and generate an RSS feed of the BBC's responses to complaints.
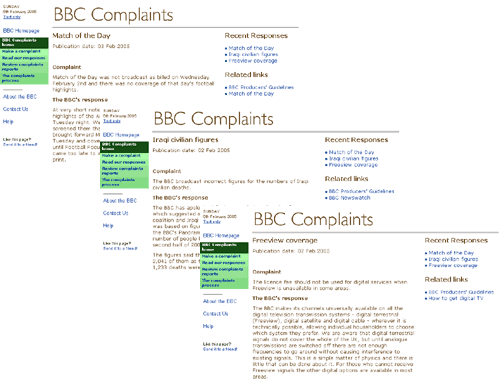
The script works by scraping the "Most Recent Responses" section from the Read Our Responses page, then running off to fetch the opening couple of paragraphs of each response to act as the <description> element in the RSS feed. So I can now pop it in as a subscription within my bloglines account, and keep up-to-date on it for work purposes without having to visit the site.
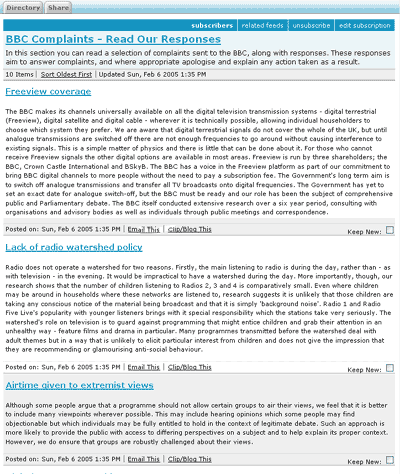
Of course, being based on screen-scraping the HTML, it is no doubt going to be very brittle, and a case of break followed by iterate followed by break followed by iterate. I suspect it won't validate as proper RSS 0.91 either, as I can't control which HTML tags might end up included in the <description>. And I so far haven't bothered to extract the date-stamp of the actual posts.
But, if these guys can parse something as difficult as Hansard, surely even my tiny grasp of perl should help enable me to glean the information I need to do my job :-)
What a disaster giving the BBC monopoly coverage of the Olympics, if medals were awarded for chat and spin plus useless interviews then the BBC would top the table.
They used to be the greatest at cover but its all slipped with continual studio guests and less action than ever.
Could we hope for a return to previous cover with professionals fronting events and the focus being on the competitor rather than the presenter.
Very disappointed sports fan.