The impact of duplicate content on social media success for newspapers
On Monday I published an e-book entitled 'Measuring UK newspaper success with social media'. This featured the results of a study which captured 3,500+ URLs from 50+ media websites that proved popular across 8 social media and link sharing services.
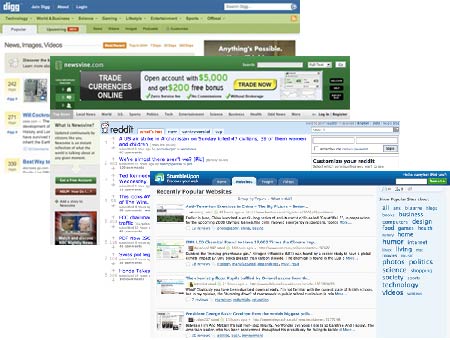
I've also been blogging about some other results from the study, concerning local newspaper and freesheet content. Today I wanted to look at the impact duplicate content publishing has on social media, and search engine, success.
Duplicate content
'Duplicate content' has been a debating point amongst webmasters and SEO practitioners for some time. The key question has been how do search engines detect duplicate content, and how do they rank or penalize sites with duplicate content? This issue also now applies to social media optimisation. My study showed up some easy ways to illustrate this problem, using examples from This Is London of content that had also appeared on the Daily Mail site.
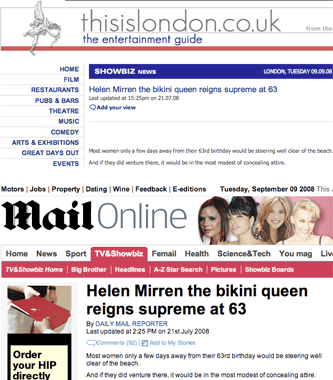
Helen Mirren's bikini
"Most women only a few days away from their 63rd birthday would be steering well clear of the beach."
Leaving the debate about whether grandmothers should ever be allowed out to the beach for another day, this was the opening line of both a This Is London story and Daily Mail story about Helen Mirren's choice of bikini.
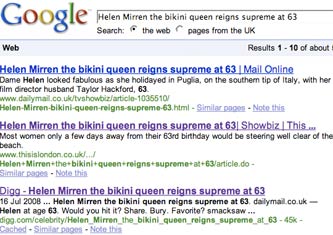
As you can see, Google indexes and ranks both versions separately.
The article also became popular on different social media services - from both newspaper web sites. The This Is London version was listed as a 'top seed' on Newsvine, and was one of two URLs I noted from This Is London on that service. The Daily Mail URL for the story became a popular, if crassly puerile, attraction on Digg. A follow up article about men's reactions to the bikini becoming popular for the Mail on StumbleUpon.
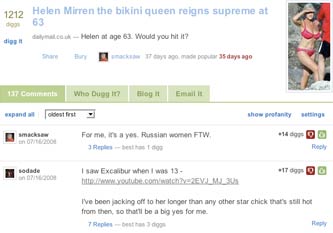
The problem here is not just that at some point there is a risk that Google might decide to depress the rankings of one, other or both sites because they are producing the same content. Additionally the two web properties are dividing their potential social media votes, and it seems randomly down to which version of the story first gets shared or bookmarked as to which URL gathers popular momentum on sites like Digg.
Andrew Malone on China
Another example during the course of my social media study was an opinion piece about the impact of China in Africa written by Andrew Malone - "How China's taking over Africa, and why the West should be VERY worried". The This Is London version became popular on Delicious during the month I was monitoring media URLs. The Daily Mail version, meanwhile, hit the front page of Digg, Newsvine...and also Delicious.

Clearly, the total bookmarking score of the article is being divided between the two versions. In this case it was not so significant, since with 50+ bookmarks each, both versions became 'popular' on Delicious. The problem is that other articles may gain 30 social media 'votes' each, and consequently neither of them will reach that level of exposure. A combined total of 60 for one canonical URL would have placed the story on the Delicious homepage.
We can also safely assume that the same is happening to the backlinks to the article all around the web, which means that neither site is extracting the full 'Google juice' it could be accruing either.
The relevence of social media icons
This article is also interesting from the point of view of trying to determine whether the positioning and presence of 'sharing icons' on websites is a significant factor on an article becoming popular.
The Daily Mail version of Malone's article was popular on Delicious, Digg, and Newsvine - all services that the site has links to.

The This Is London version was popular on Delicious and Reddit - also both sites that This Is London invites readers to use with links.
However, you can also note that the Daily Mail has a link to Reddit, yet it was the This Is London version that gained traction there. Vice-versa, This Is London has a 'Digg' button, but it was the Daily Mail edition of the story was the one that reached the front page of Digg.
Divided interactivity
As well as diluting their potential social media and search engine 'juice', the two sites have also attracted a different level of comment. Where the piece appears on This Is London there were (at the time of writing) 10 comments from users.

On the Daily Mail version of the article there were none - although maybe they are just stuck in the moderation queue.

Next...
Next week I'll be looking at further data from my in-depth study of the media URLs becoming popular on social bookmarking and link sharing sites. I'll be moving away from newspapers, and instead, concentrating on the 24 hour television news market, with a profile of CNN's success with social media.
I'm sure it'll quickly become required reading.