"People, Places, Subjects" - BBC Topic and Guardian keyword pages: Part 4
Over the last few days I've been drawing some comparisons and contrasts between the way the BBC has launched their new 'Topics' aggregation pages, and the way that The Guardian achieves much the same effect with 'keyword index' pages. So far I've looked at things like external linking, RSS feeds, URL structure and the classification style being used.
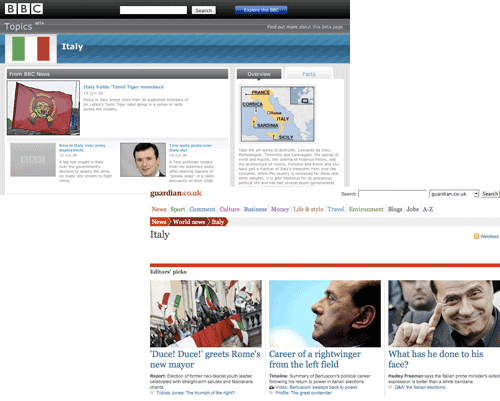
Similarities with search
As has been made clear on the BBC's Internet Blog, it is the search team at the BBC that has been developing and delivering the Topic aggregation pages, and I was interested to see how the content different from a search results. The results are not the same, which leads me to wonder exactly how automated the process currently is.
Take the Autism page for example. On the Topic page there are two external web links listed, with a brief description. If you search for 'autism' on the BBC site however, you only get one of these links returned in the web panel.
Although the nas.org.uk link appears in both sets, it has different descriptive text applied. On the /topic page it is listed as a 'Charity championing rights and interests of all people with autism', whist on the search results it is a site providing 'Information, advice and details of day and residential centres for the care and education of autistic children'.


If the /topics project is to scale up to producing hundreds and possibly thousands of pages, I'm not sure that providing bespoke text for external links when they are already 'BBC recommended websites' in search results is a particularly sustainable approach. [1]
Comparing the search results for 'autism' and the topic page for 'autism' shows that other areas of the new page are more than simply a re-badged search result page. For example, the audio and video content returned by search, and the results displayed on the topic page also differ.
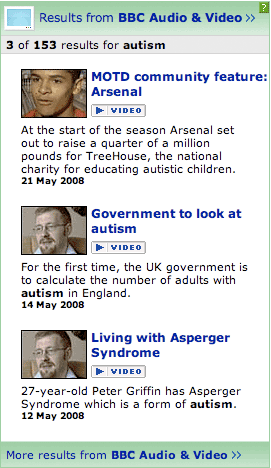
One other point about the 'autism' page. At the top of the page there is a brief description of the topic, with the option to 'Read more'. This expands to give a brief overview of the topic.
It isn't clear where this content has been sourced from.
Again I worry that this is more bespoke content production, rather than true 'aggregation' of content from around the rest of bbc.co.uk. Certainly, there is no credit to an external origination of the copy. Keeping these text snippets fresh and maintained across a wider range of /topics pages will be another factor affecting the editorial scalability of the system.

Always on topic?
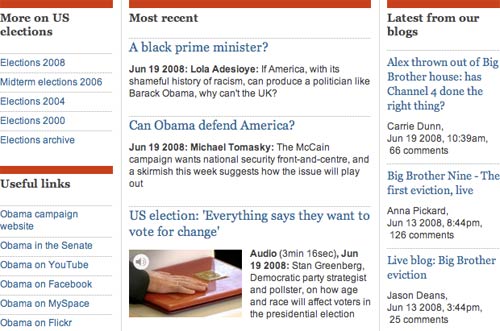
One advantage that the BBC system seems to have over The Guardian is that their 'topic' pages always seem to consist of elements that are exclusively on topic. Sometimes on The Guardian site there are some weird juxtapositions between content that is related to the keyword, and some content elements that are just 'the latest of a particular type of thing'. An example of this when I was researching this piece was the Barack Obama page.
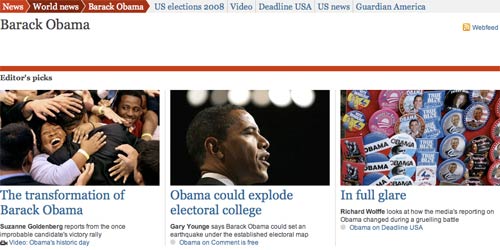
All of the content pieces are about Barack Obama, and The Guardian gives more information clues to users about the 'topic' by including related links to other candidates in the U.S. Presidential Contest.
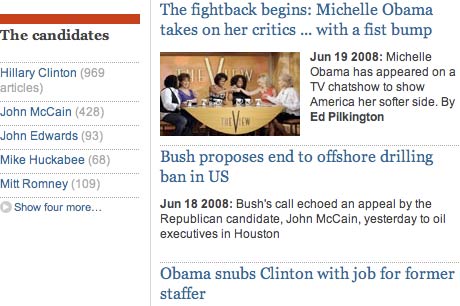
Yet, in the midst of it was also a column with the latest content from The Guardian's blogs, which was almost entirely dominated by the news of the forced eviction of one of this year's UK Big Brother housemates. This struck a very odd note on a page so obviously otherwise focussed on a serious news topic.
Next...
In the final part of this series, I'll be looking at how the BBC is gathering feedback on their 'Topics' product, and explaining why I think the fact that 'Topics' is a product shows a difference between the two organisations.
[1] I note that in the two weeks since I did my initial research for this blog post, the BBC's search results page has changed, and the nas.org.uk link is no longer appearing as a recommended web link when you search the BBC for information on 'autism'. [Return to article]
Hi -
Great post, and fair point about the discord between the related blogs and Barack Obama on the Guardian. The reason for this that the blogs CMS is currently only loosely coupled with the core CMS.
So in some places it works well, and others it doesn't. Because we have plans afoot - we didn't do such a great job of making the link between the CMS's great - except in a few cases, such as travel.
This will start working a lot better shortly, as we more closely integrate the blogs IA with the CMS.
Cheers
Stephen